2023年中国工业互联网安全大赛决赛-misc
2023年中国工业互联网安全大赛决赛-misc
刷csdn看到了这个比赛 顺手下了附件也来做一做
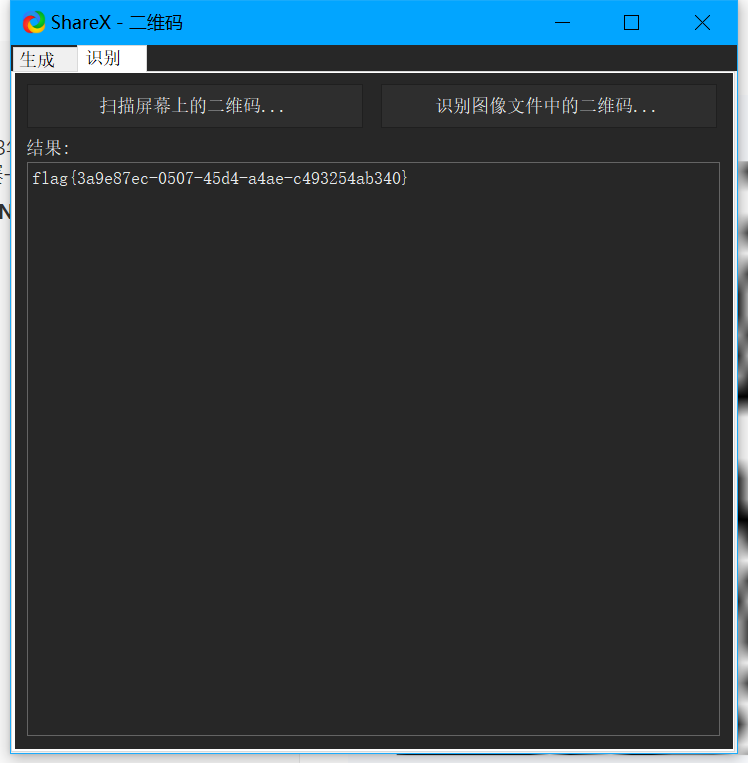
DNS_Query(DNS流量提取数据 二维码)
拿到一个dns流量 看到info里面有东西
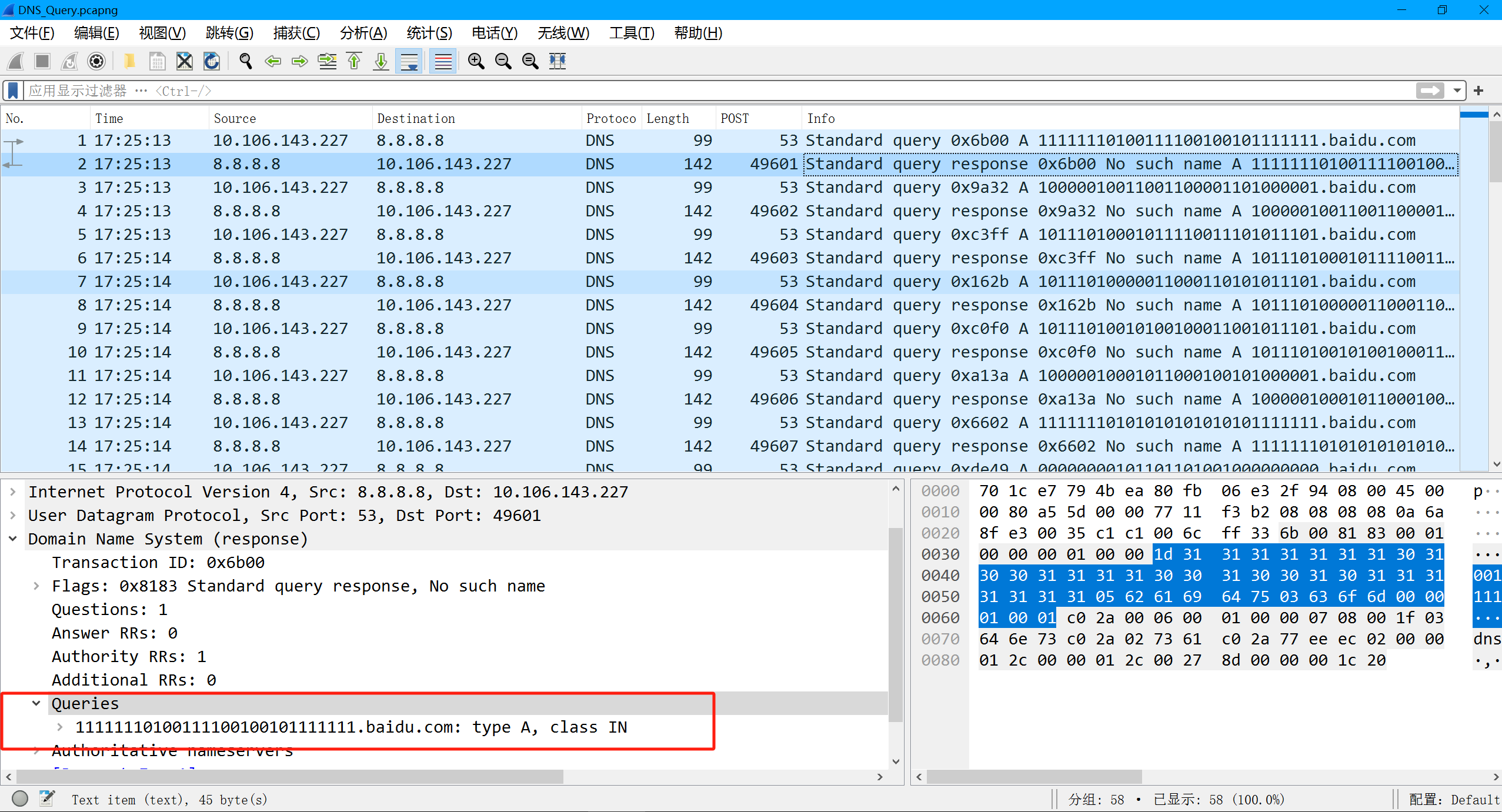
但是每两条里面的info都是一样的 那我们先过滤一下
frame.len == 142
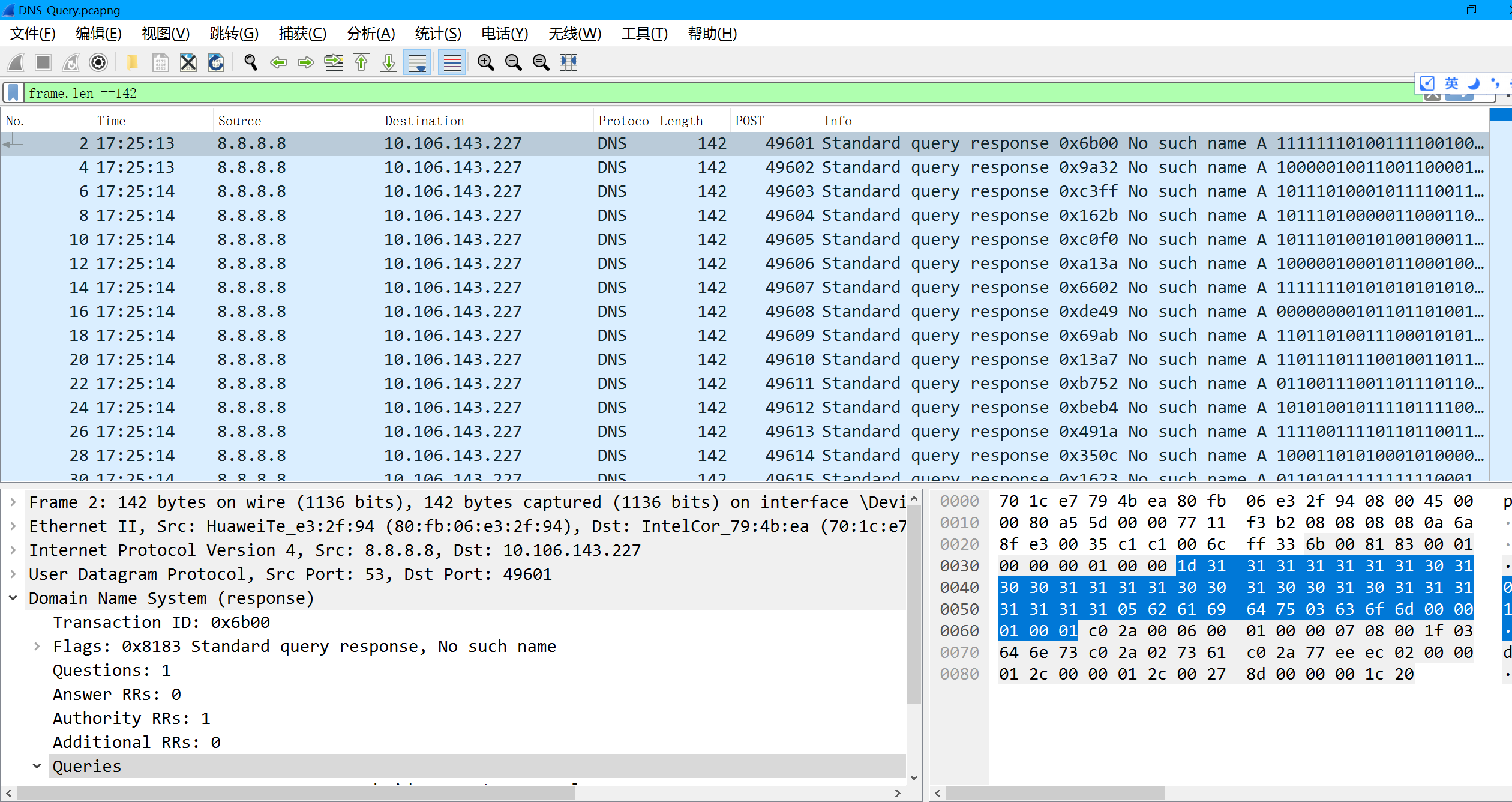
写tshark语句把里面的信息提取出来
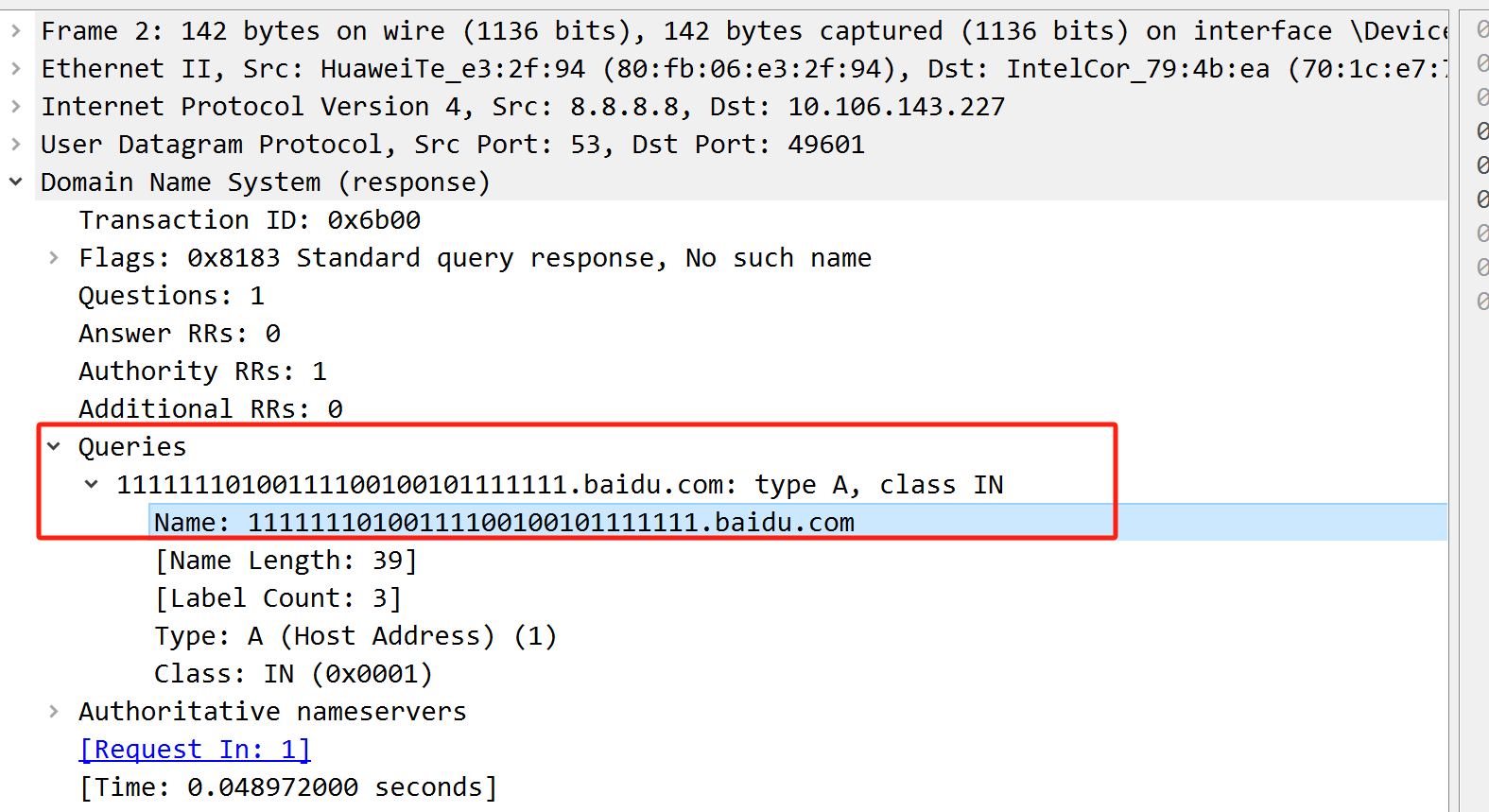
tshark -r DNS_Query.pcapng -T fields -Y "frame.len == 142" -e "dns.qry.name" | awk '{print substr($0,0,29)}' | tr -d '\n' >data.txt
-Y 是筛选数据包
-e 由上图可以看到我们想要提取的数据是在queries的name字段的
awk 对提取出来的文本进行处理 提取从第一个字符开始的连续29个字符 这里我们只需要数字部分
tr 进一步处理将每行后面的换行符去掉
猜测这段字符是二维码 写脚本进行转化
from PIL import Image
from zlib import *
MAX = 29
pic = Image.new("RGB", (MAX, MAX))
str1 = "1111111010011110010010111111110000010011001100001101000001101110100010111100111010111011011101000001100011010101110110111010010100100011001011101100000100010110001001010000011111111010101010101010111111100000000101101101001000000000110110100111000101011010000011101110111001001101110011110001100111001101110110110011000101010010111101111001100110111111001111011011001101110001110001101010001010000101111001011010111111111100011001001011100110111110011101001111010110001110100001111001110001001111000001111101111110101100001101101110010111011101111000111011101101011100000000000101111100110000101001011111111010000000010100101101110001010011111110001010010101101011100100000100100001001001000100001011101011100111001111111001010111010111010110111100101001101110100100001100010000100111000001010101111100101111110111111110110110010000100010000"
i = 0
for y in range(0, MAX):
for x in range(0, MAX):
if str1[i] == '1':
pic.putpixel([x, y], (0, 0, 0))
else:
pic.putpixel([x, y], (255, 255, 255))
i = i+1
pic.show()
pic.save("flag.png")

gigached(lsb隐写 AES加解密)
压缩包里面有注释 应该是一段加密逻辑 但是我拿到的附件是已经被解压的了 只能看wp里面的了
def encrypt(key, source):
source = source.encode()
key = key.encode()
key = SHA256.new(key).digest()
IV = Random.new().read(AES.block_size)
encryptor = AES.new(key, AES.MODE_CBC, IV)
padding = AES.block_size - len(source) % AES.block_size
source += bytes([padding]) * padding
data = IV + encryptor.encrypt(source)
return data
给的这个文件 先看一下类型 是一个iso media

改个后缀名 使用ffmpeg或者foremost 进行分帧 题目介绍是lsb on movie 那视频文件没法进行lsb隐写 估计是在视频的某几帧里面进行lsb隐写
foremost gigached 或者
ffmpeg -i gigached ./output/outr%04d.png
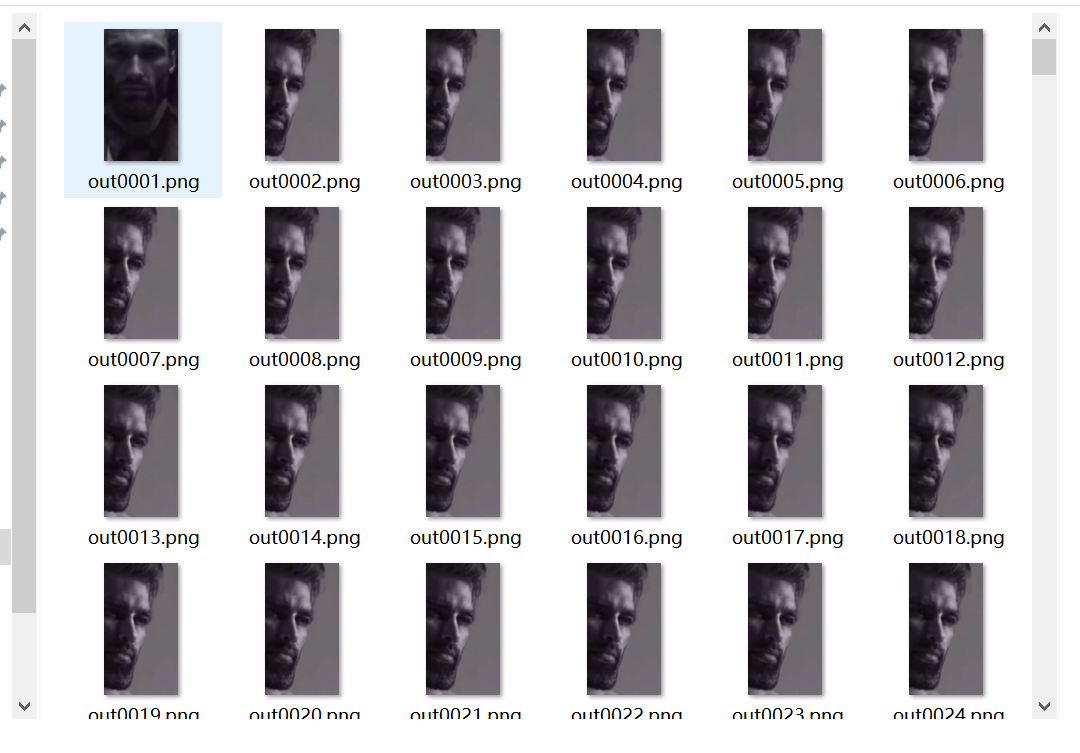
直接使用stegsolve或者zsteg提取隐藏信息就可以了
8:dp6UYHfO
8:NZhyAEYx
8:Js8o3024
8:l+je3k5k
8:aJmsL+Hx
8:w43oQ3oz
8:XjTT3/LQ
8:qF4fuu/w
8:MNqZVqiA
8:Q3vzixxY
8:QYbnuQ==
8: the key
8: isgYpt3
8:GvM7X1A1
3:CoT
将这个内容写入1.txt 写个脚本处理一下
with open("1.txt", 'r+') as f:
line = f.readlines()
new_lines = []
for i in line:
i = i[2:10:1]
new_lines.append(i)
f.writelines(new_lines)
dp6UYHfONZhyAEYxJs8o3024l+je3k5kaJmsL+Hxw43oQ3ozXjTT3/LQqF4fuu/wMNqZVqiAQ3vzixxYQYbnuQ==
the key isgYpt3GvM7X1A1CoT
根据前面的加密方式写解密脚本
from Crypto.Cipher import AES
from Crypto.Hash import SHA256
from Crypto import Random
import base64
def decrypt(key, data):
data = base64.b64decode(data)
key = key.encode()
key = SHA256.new(key).digest()
IV = data[:AES.block_size]
decryptor = AES.new(key, AES.MODE_CBC, IV)
decrypted = decryptor.decrypt(data[AES.block_size:])
padding_length = decrypted[-1]
decrypted = decrypted[:-padding_length]
return decrypted.decode()
encrypted_data = "dp6UYHfONZhyAEYxJs8o3024l+je3k5kaJmsL+Hxw43oQ3ozXjTT3/LQqF4fuu/wMNqZVqiAQ3vzixxYQYbnuQ=="
key = "gYpt3GvM7X1A1CoT"
decrypted_text = decrypt(key, encrypted_data)
print(decrypted_text)
# flag{d53dbf36-444a-471d-a663-91a9e6f400e0}
hellofromspace(udp流量提取图片 图片异或)
打开流量包 看一下协议分级 基本上全是UDP 那就直接追踪一下UDP流 看到两部分flag 一个在flag_part1.txt中 一个在flag_part2.png中
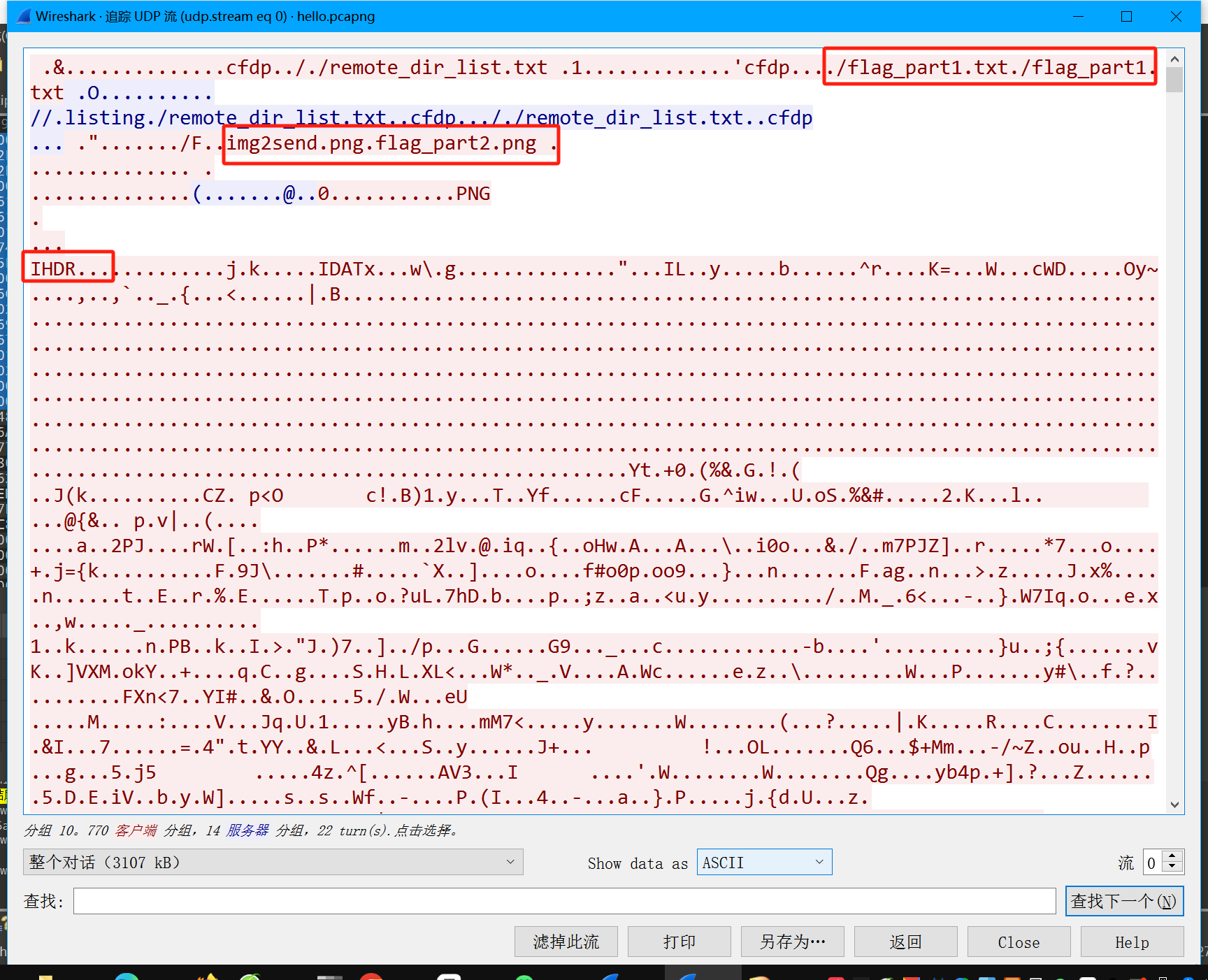
追踪udp流发现只有一个流 第一部分flag可以直接在里面搜出来
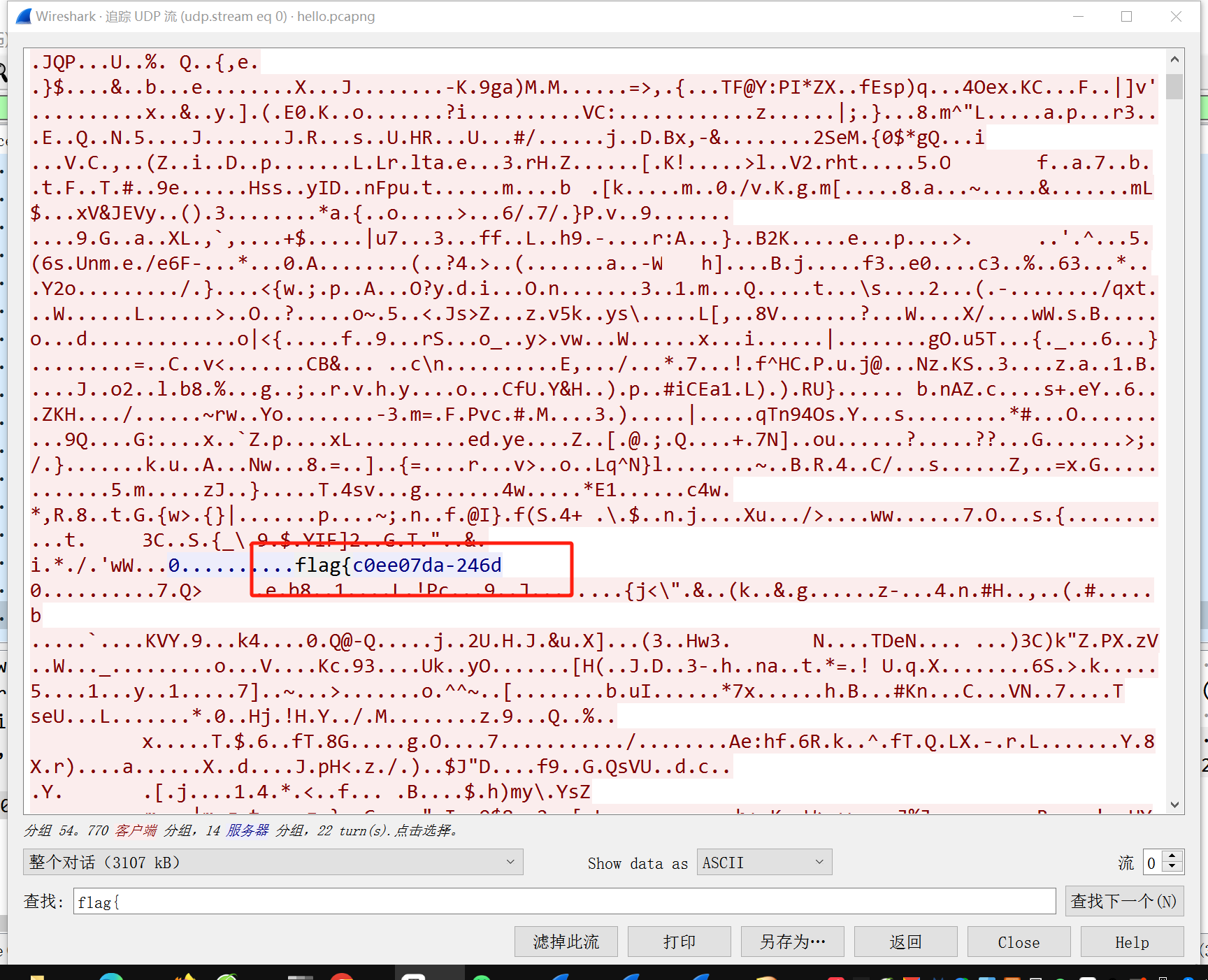
flag{c0ee07da-246d
将数据形式改为原始数据 在010editor里面保存为新文件 1.png
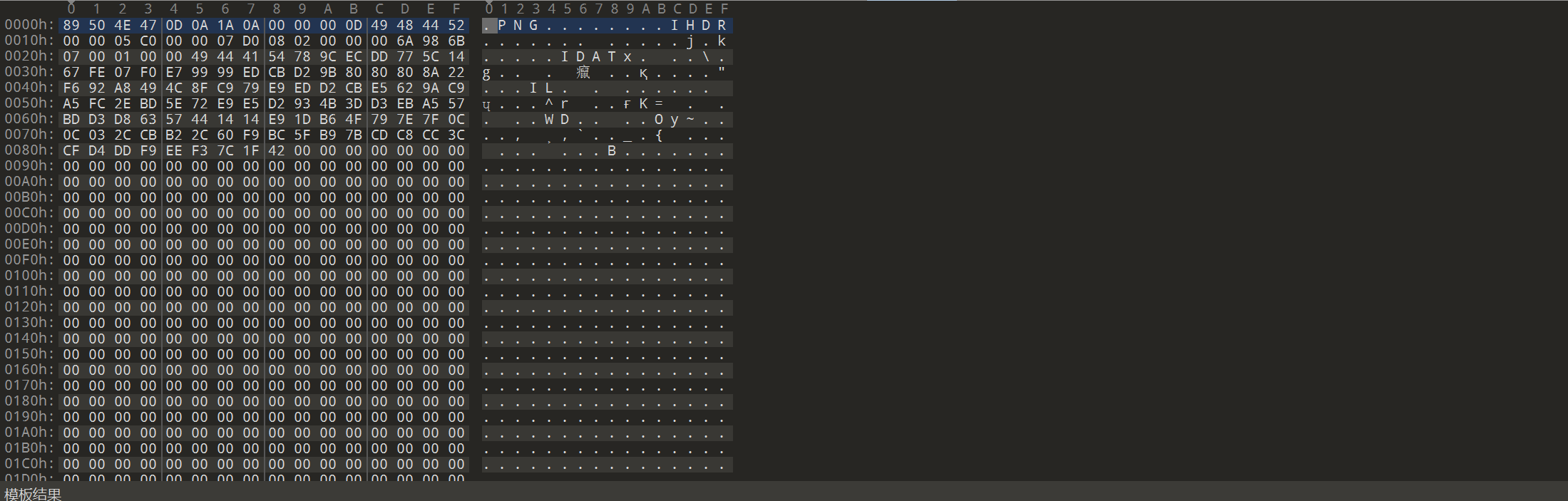

看着有点不对劲 很明显是缺少了完整的图片结构 但是末尾也确实有正确的图片尾

猜测是中间的部分出了问题 返回去在看一下 图片头是出现在长度为1189的包中的 后面也有很多长度为1189的包
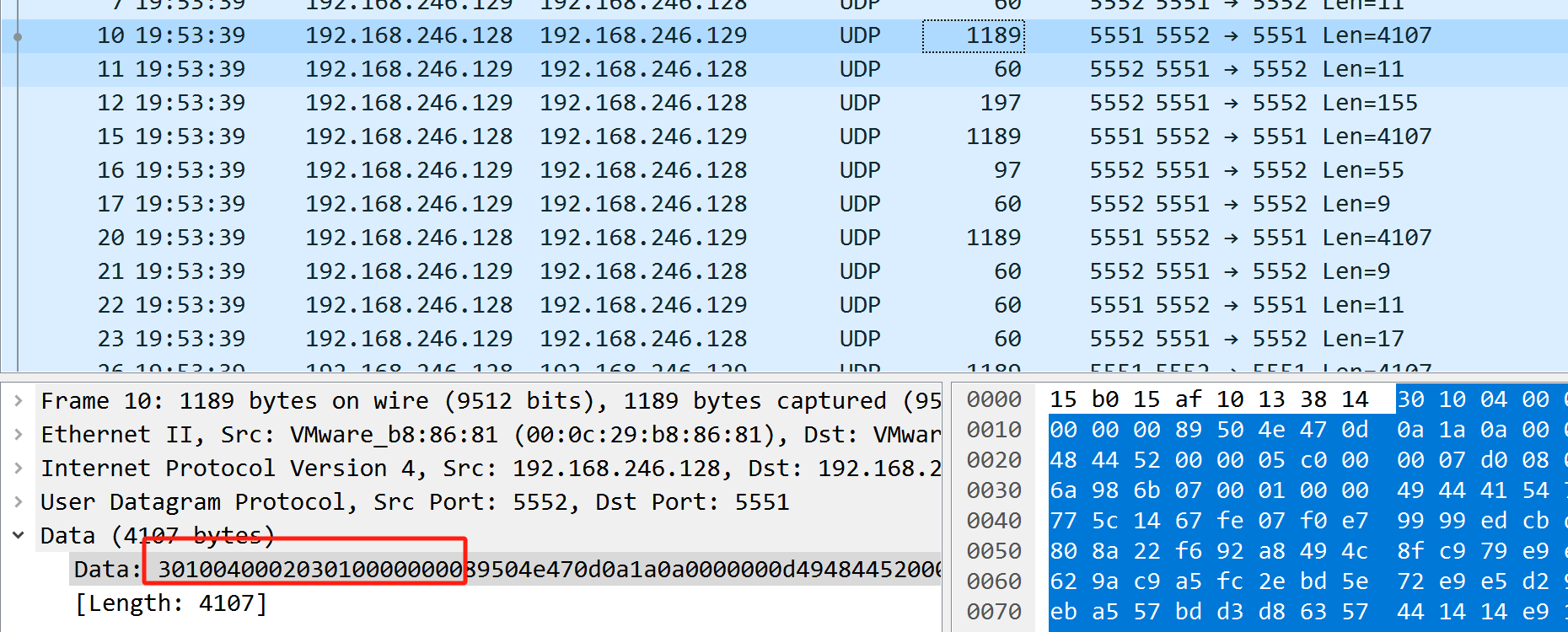
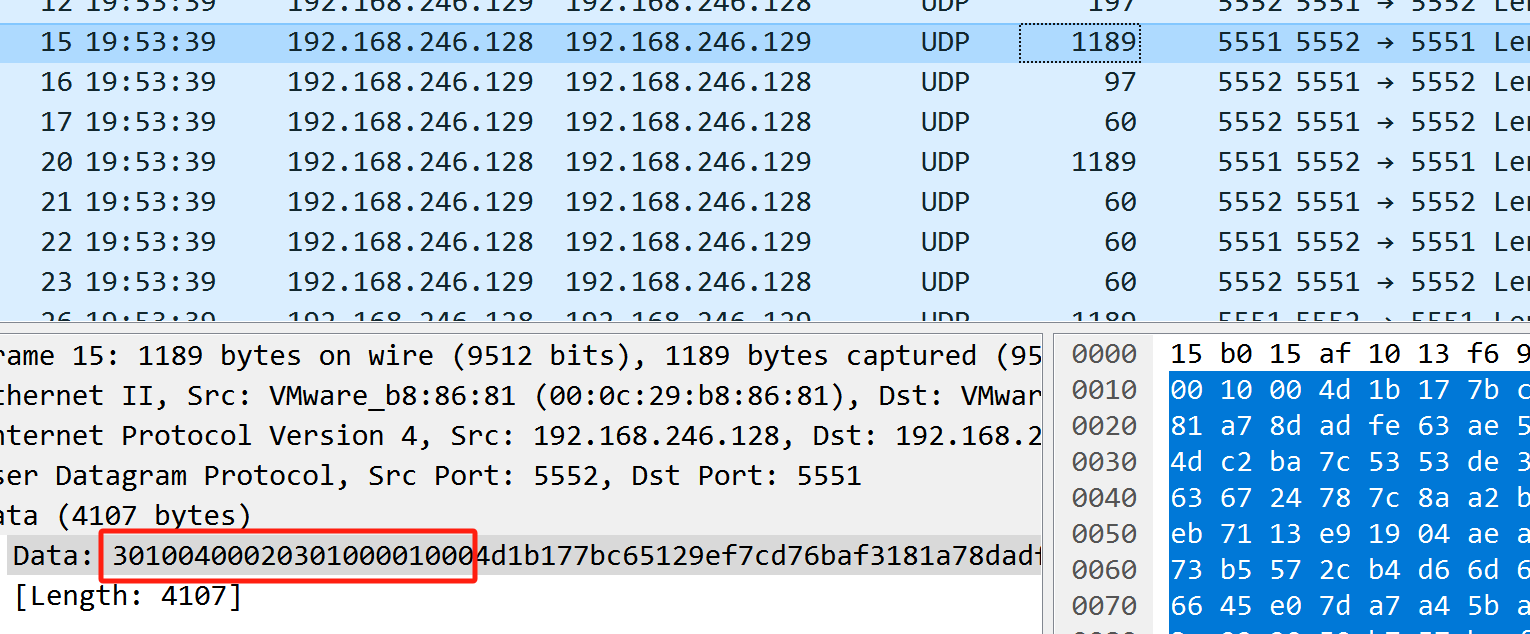
png头是从第12个字节出现的 观察下一个长度为1189的包 看到第10个字节数字加了1 看来是计数的 使用的是16进制计数法 顺序计数 那就不用再单独排序了 考虑到文件尾是出现在长度为289的包 那我们就筛选长度>=289的包
udp && frame.len >= 289
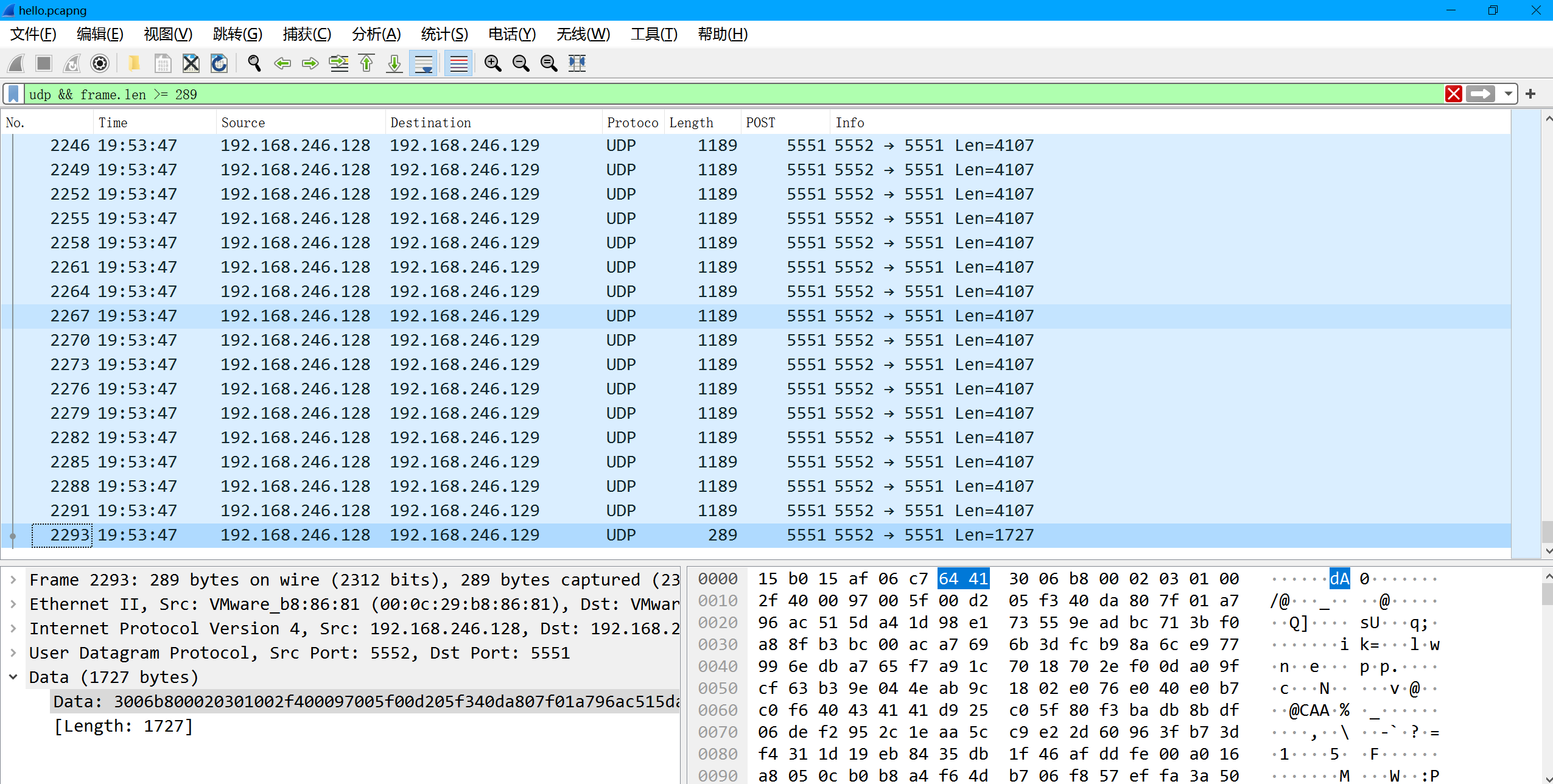
tshark提一下数据
tshark -r hello.pcapng -T fields -Y "udp && frame.len >= 289" -e "data.data" | awk '{print substr($0,23)}' > hex.txt
再把数据放在010里面转储为png图片

看起来和题目附件里面的original.png一样 猜测是双图盲水印 但尝试过后发现不是 是两张图片异或 使用stegsolve就可以 先打开一张图片 再点Analyse–Image Combiner
得到一张图片 隐隐约约看到后半段flag
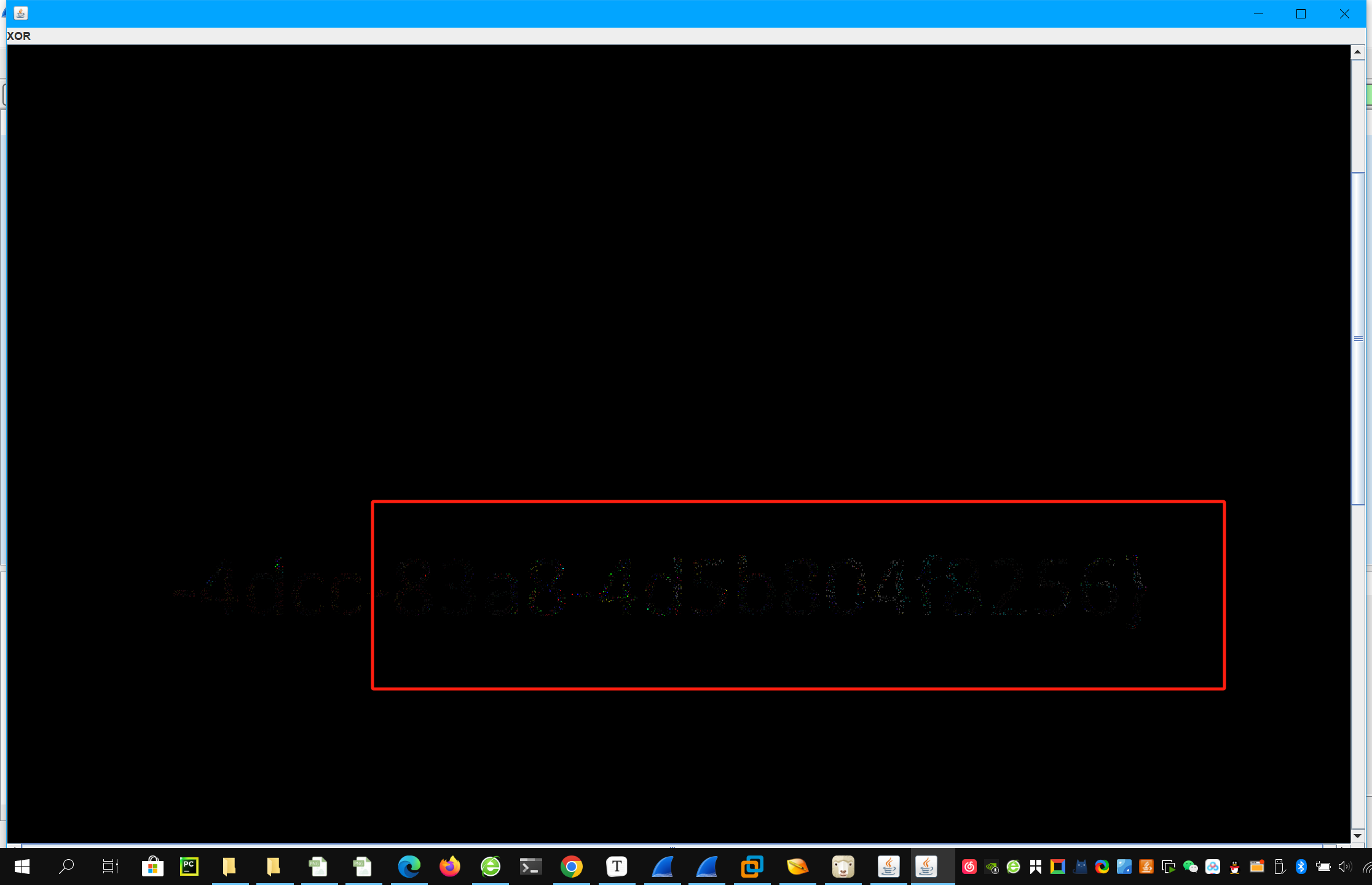
将其保存下来 找个看的清楚的通道
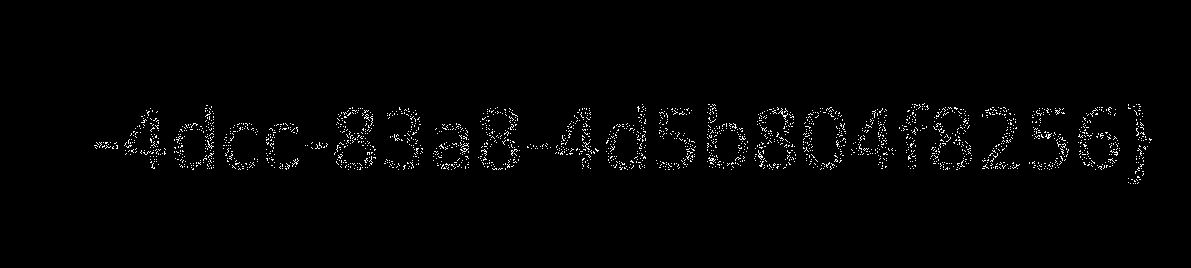
threepages(苹果png解析bug lsb隐写 js函数调用)
拿到流量包 看一下http导出 关键的文件就是三个html文件page1.html page2.html page3.html 提取出来看看
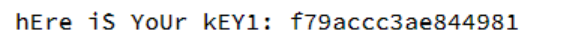
得到key1
f79accc3ae844981

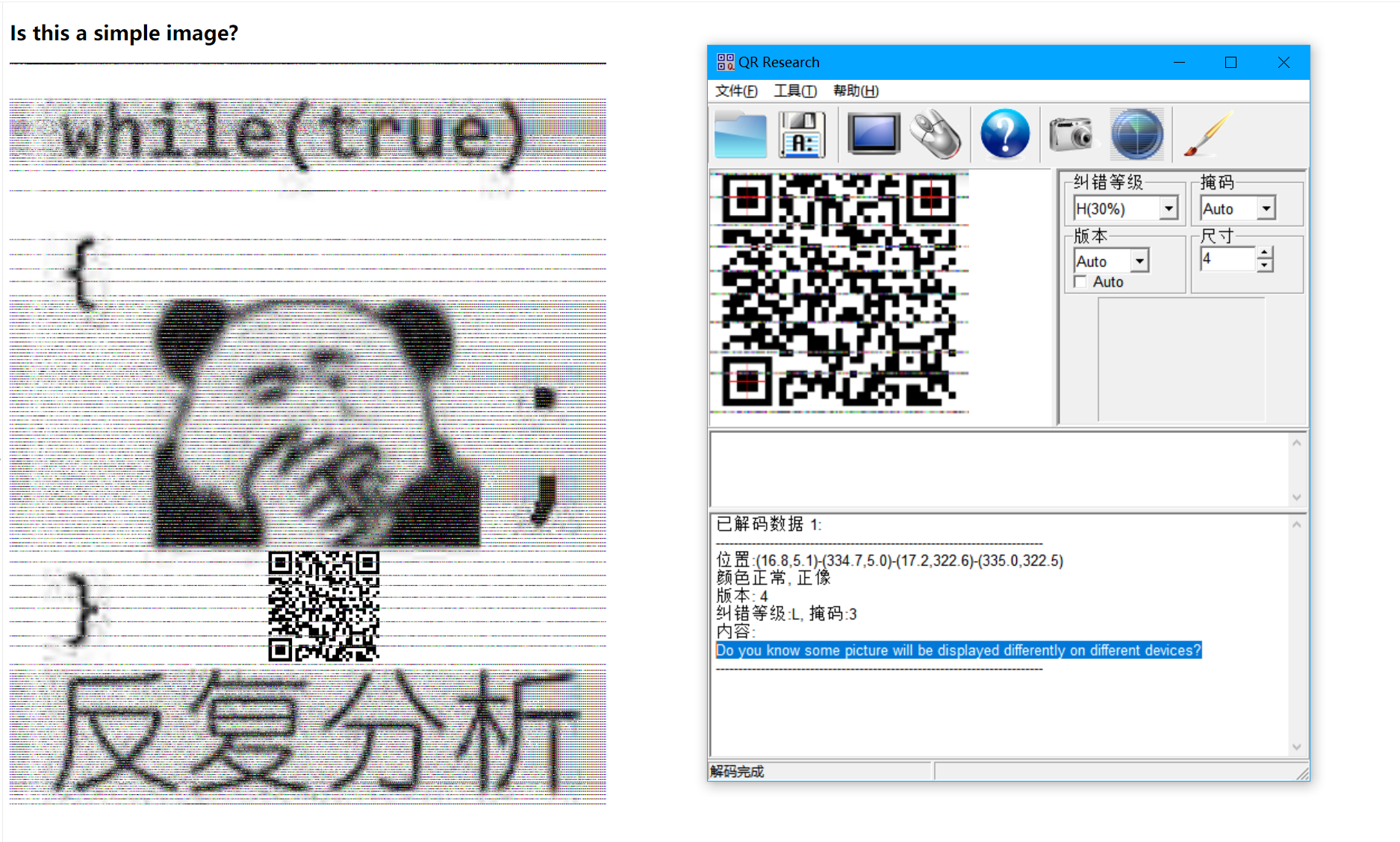
扫码得到一段话
Do you know some picture will be displayed differently on different devices?
指的是在不同设备上显示不同的图片 搜了一下 是苹果png解析bug
找一个识别网站在线识别
找个在线网站读一下条形码 在线读条形码
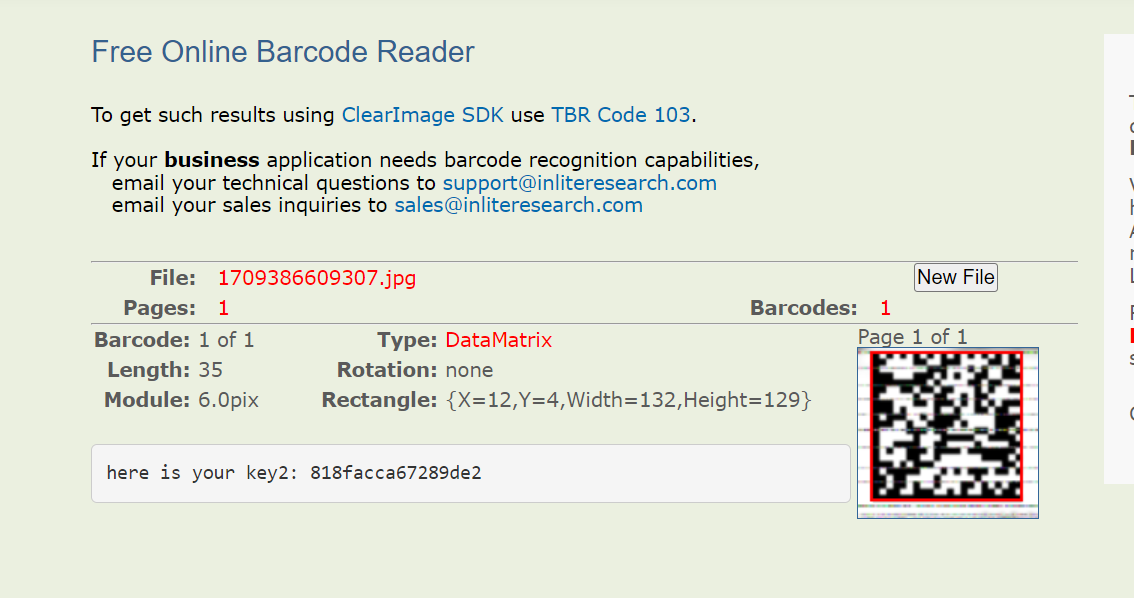
here is your key2: 818facca67289de2
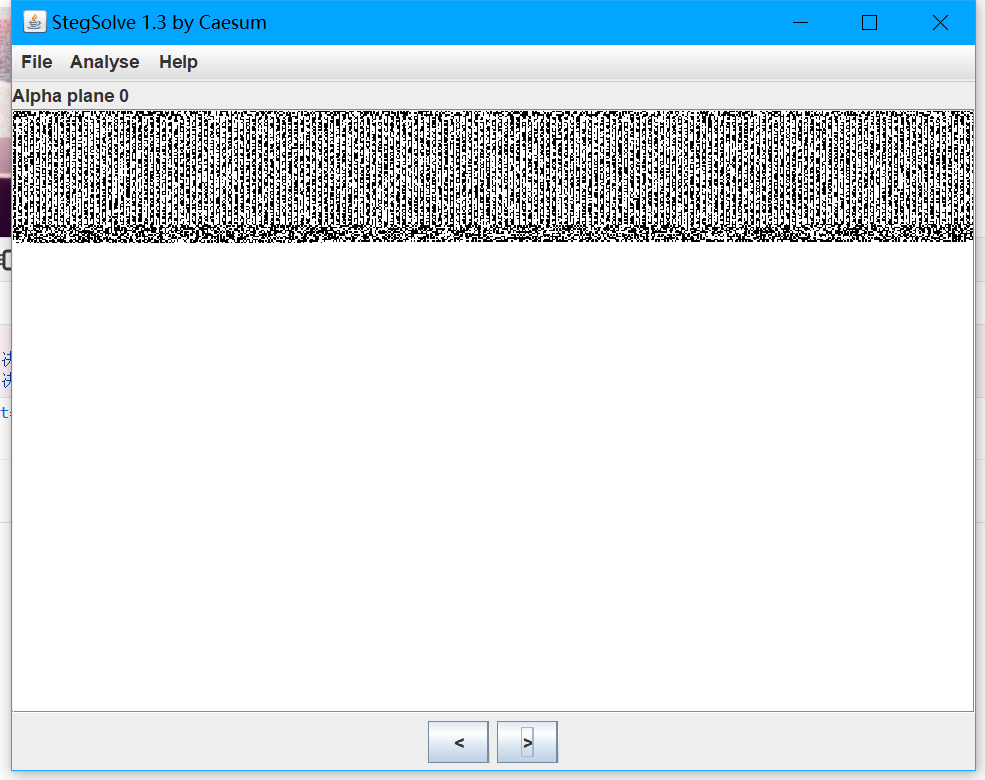
还提取出来一个p2.png 常规的png图片分析方法 看一下有没有lsb隐写 发现在alpha的全部通道均存在隐藏信息
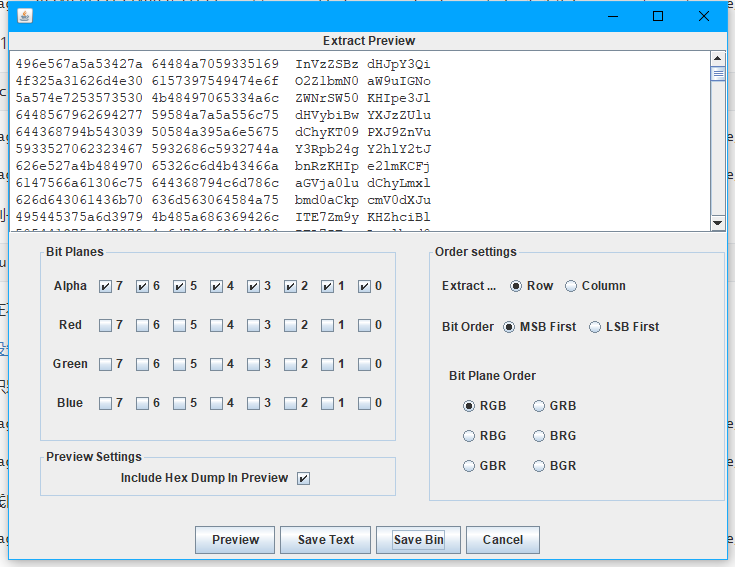
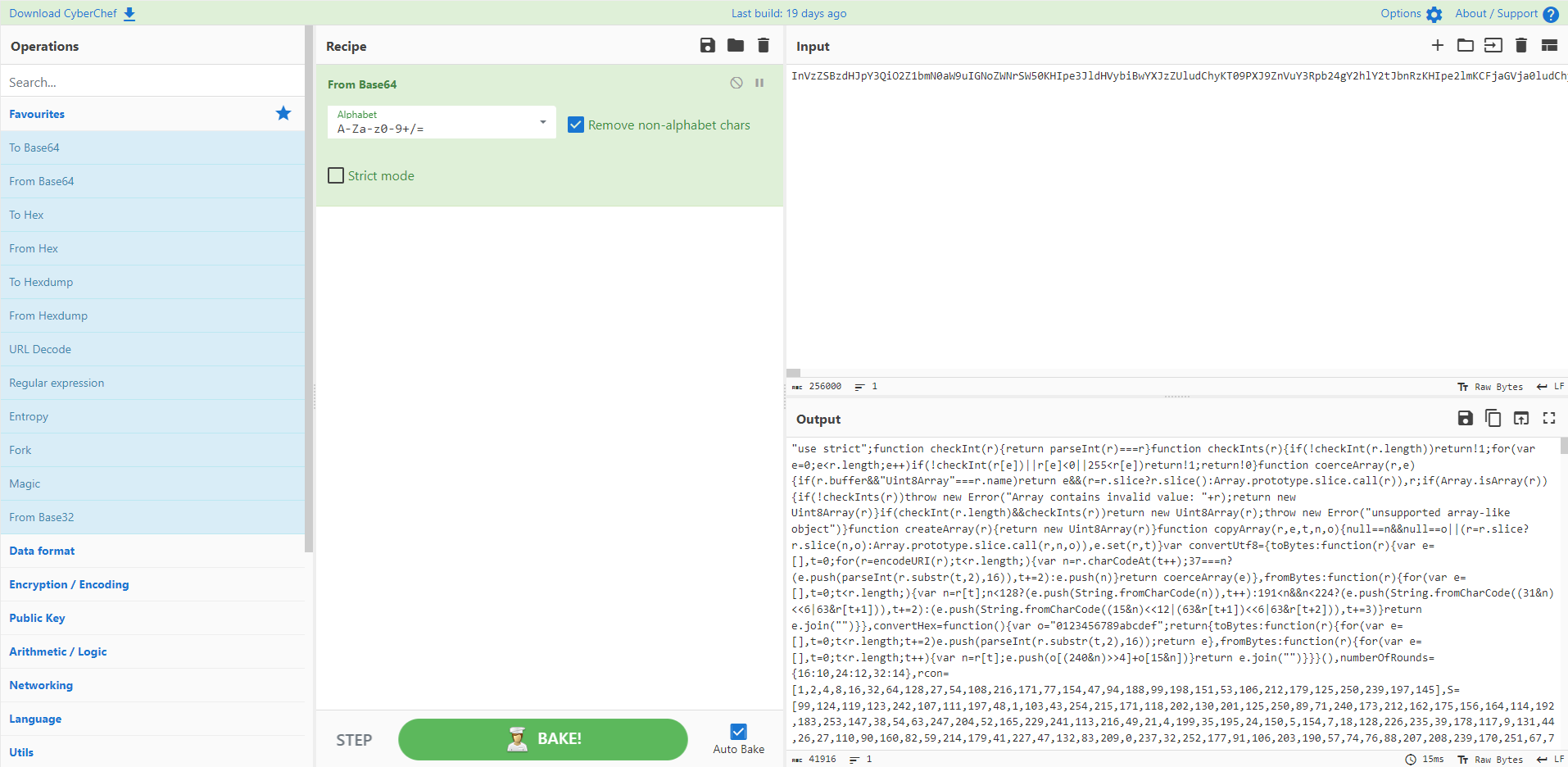
选择save bin 将信息提取出来 解base64得到源码
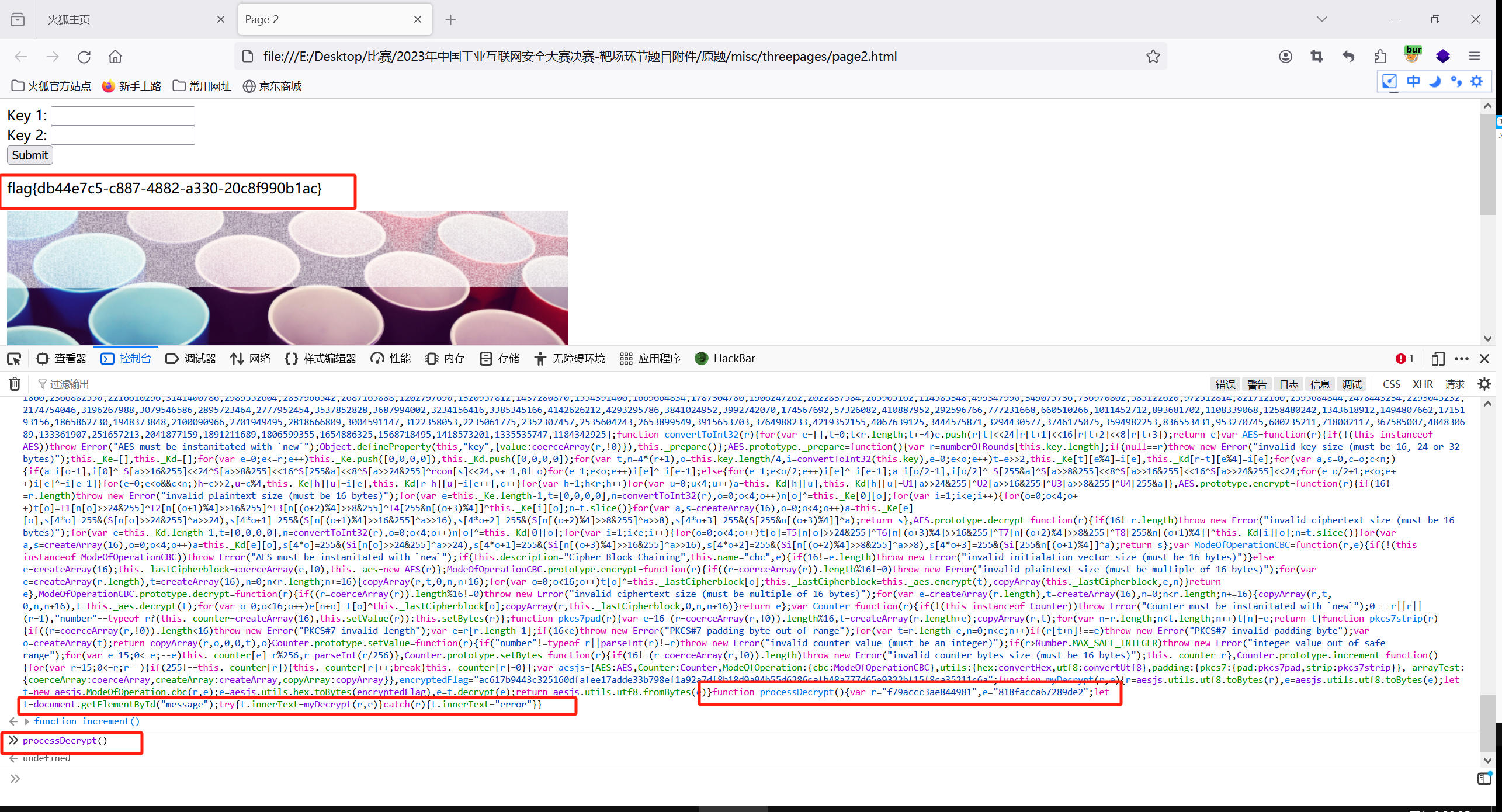
我们查看page2.html的内容 发现影响返回值的结果的是processDecrypt()函数
源码里面有关于这个函数的内容
function processDecrypt(){var r=document.getElementById("key1").value,e=document.getElementById("key2").value;let t=document.getElementById("message");try{t.innerText=myDecrypt(r,e)}catch(r){t.innerText="error"}}
那我们直接将我们得到的key1和key2赋予r和e两个参数即可
function processDecrypt(){var r="f79accc3ae844981",e="818facca67289de2";let t=document.getElementById("message");try{t.innerText=myDecrypt(r,e)}catch(r){t.innerText="error"}}
直接将赋值后的代码替换掉源码里面的部分 替换后将源码的全部复制进控制台 在调用processDecrypt()函数即可