
使用Paddle进行图片ocr识别
使用Paddle进行图片ocr识别
前言:最近也是有幸在实习中进了个专案组 主要是做一些数据分析、研判的工作 已经干了两周的时间了 本来感觉已经是上一阶段的工作可以告一段落了 但是今早在给leader看工作成果的时候 说需要我把一组整理好的图片中的信息提出来整理好 好吧 那就想办法做ocr了
对于ocr其实了解的也不是很多 大概是去年数字中国的时候?半决赛有关于这块的一个赛题 但当时也不是我主要来负责弄的 只是稍微了解了一下 还记得当时是用的Tesseract 今天拿来弄了之后发现效果不是很好 甚至还不如微信的ocr 然后就去问了我亲爱的bro

ok 那就开始学着搞一下 这东西其实使用起来还是非常方便的 就是环境安装麻烦的一批 非常需要注意版本的问题
Paddleocr2.6和3.0版本差异很大 安装的要求也不一样
开始是直接从网上找了点教学教程 照着一通敲命令 结果就是被硬控了一上午 下午的时候还是转向去翻官方文档
PaddlePaddle3.0安装
首先是需要根据PaddlePaddle 3.0安装 选择适合自己设备的方法安装paddlepaddle 我这里是选择安装最新的了

安装cuda
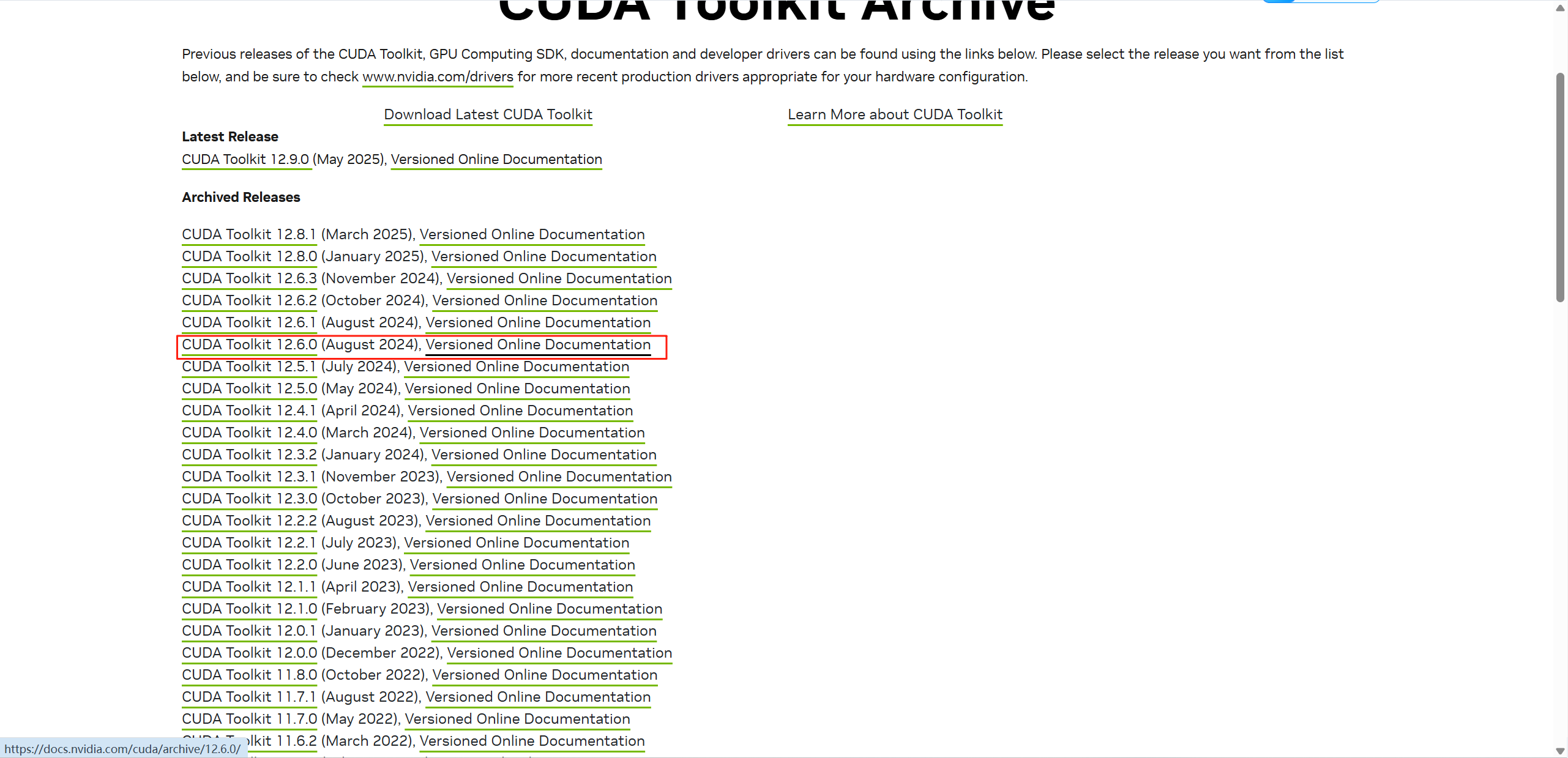
另外需要注意是cuda的版本是可以向下兼容的 这里我们看到文档中给出了cuda12.6和cuda11.8两种选择 也就是说我们后面在安装cuda的时候不能超过这两个版本
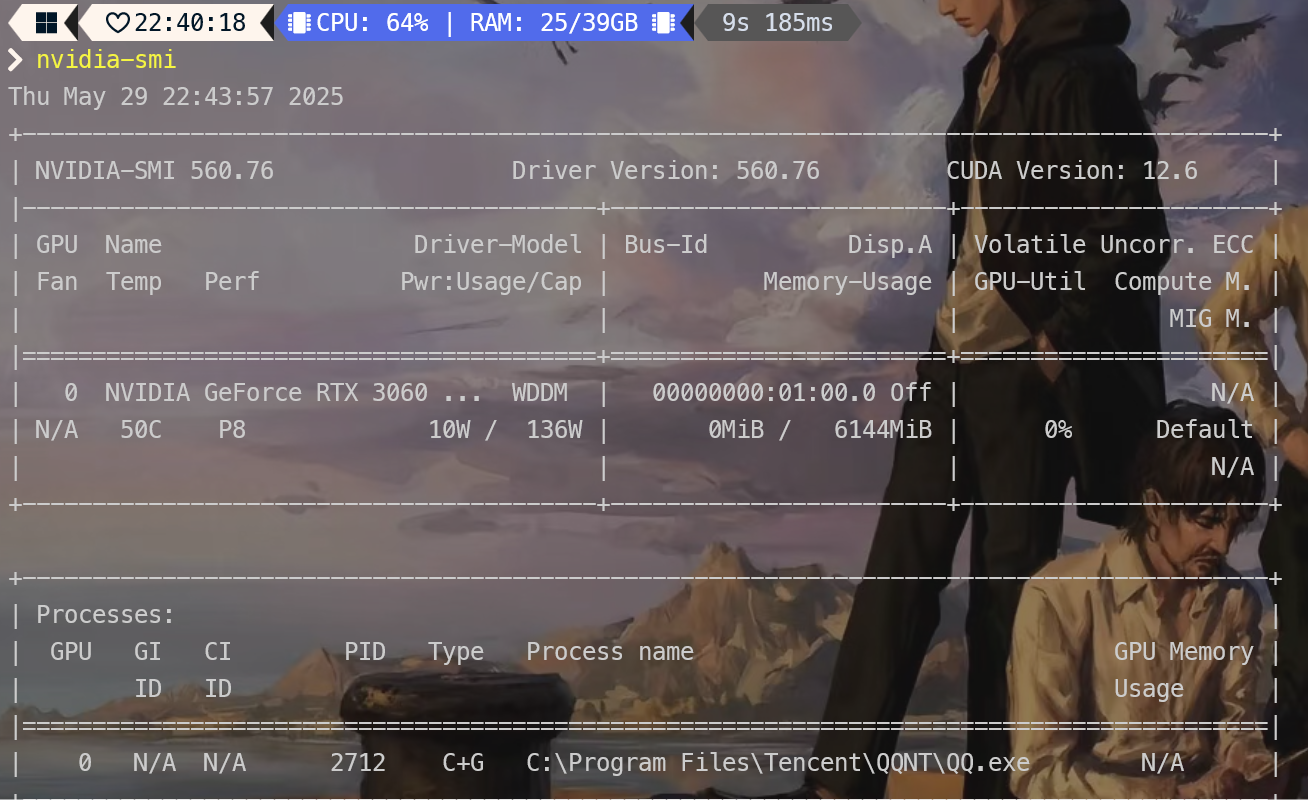
我们先看一下自己的设备支持的cuda最新版本是多少
nvidia-smi
发现我最新就是支持到12.6 那我们就选择安装12.6版本的cuda即可
然后我们要选择安装GPU版本还是CPU版本 这里我发现网上找到的大部分其他师傅自行编写的教程中都写的是安装CPU版本 CPU版本是不需要我们上面安装cuda这一步的 我开始装的时候也是选择的CPU版本 结果后面在写尝试运行脚本时发现 我的设备会自动先按照GPU的模式运行 安装的CPU版本反而是麻烦了
这里直接听劝 有GPU就用GPU版本

按照上面我的选择 安装命令是
python -m pip install paddlepaddle-gpu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
命令运行完后 开始安装cuda 进入官网 选择合适的版本

下好安装包 选择精简选项 正常安装即可
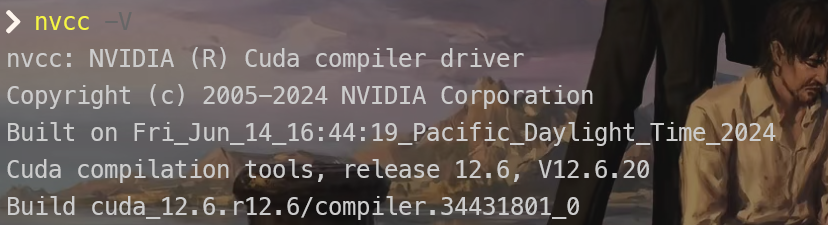
测试一下是否安装成功
nvcc -V
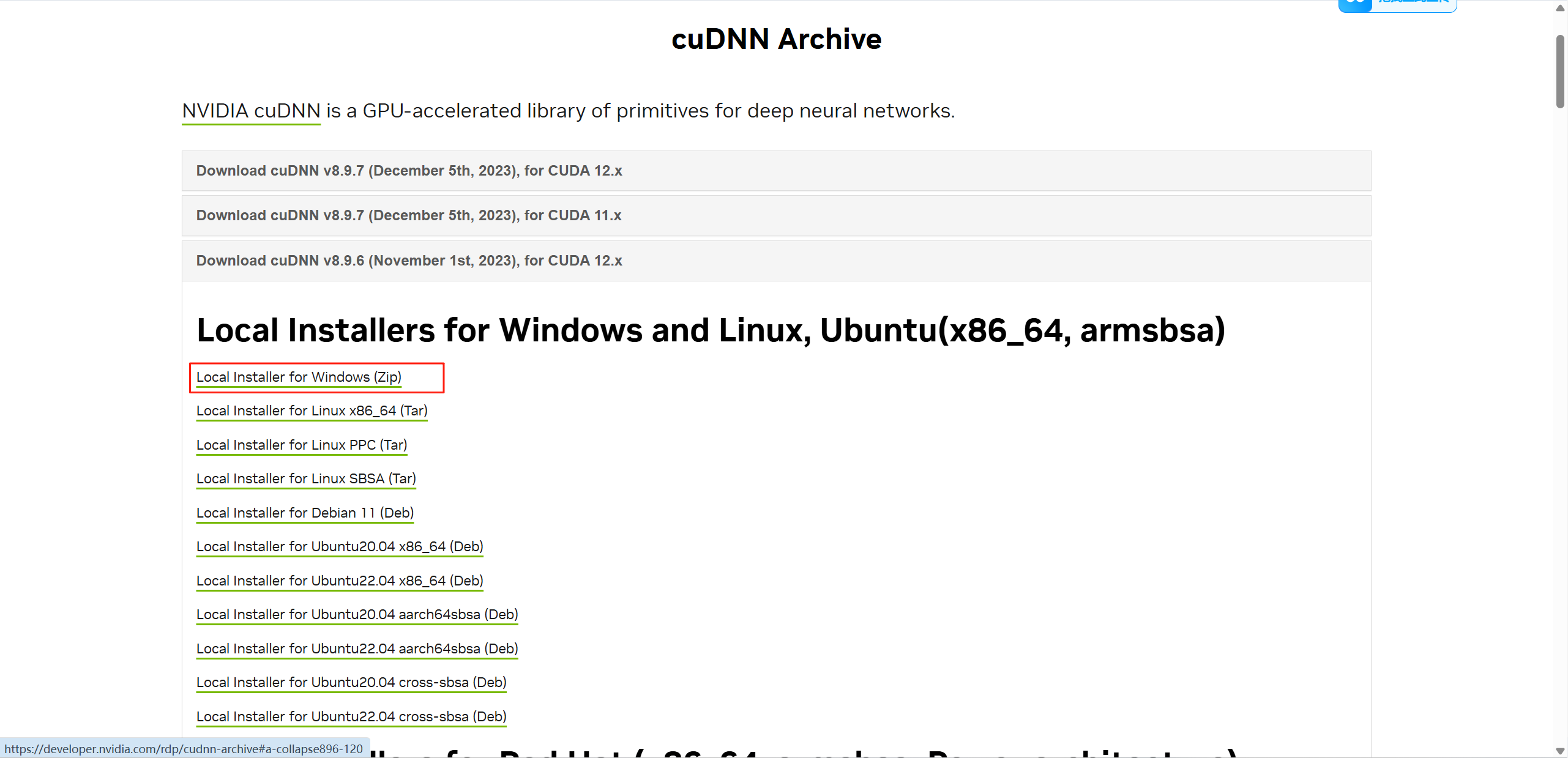
安装cuDNN
然后在安装cuDNN 用来加速cuda 下载地址 只要是满足12.x版本cuda的即可
下载下来后解压 得到

直接覆盖进cuda的安装文件夹即可 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6
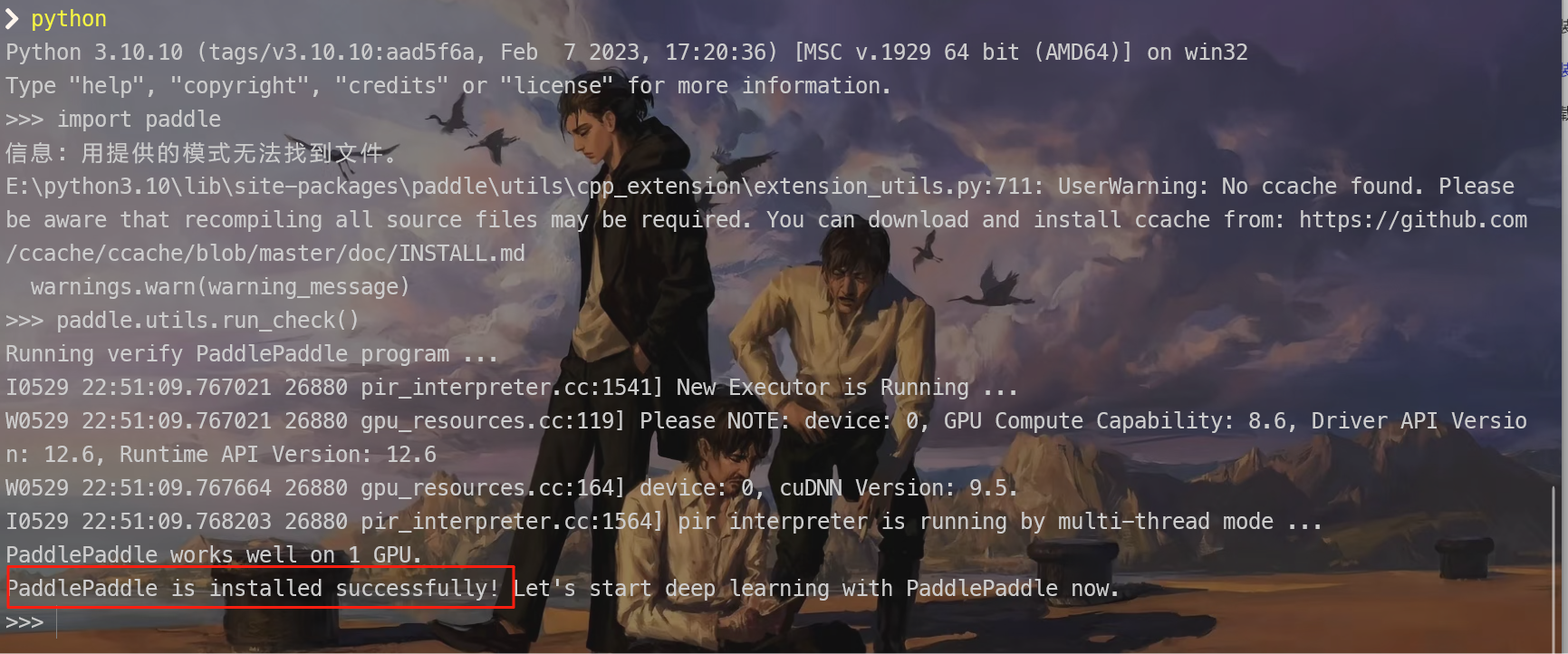
上面这几步都做完之后 我们验证一下PaddlePaddle是否是成功安装
python
import paddle
paddle.utils.run_check()
只要能看到PaddlePaddle is installed successfully! 就代表我们安装完毕
安装paddleocr
完成PaddlePaddle 3.0的安装后 我们安装paddleocr
pip install paddleocr==3.0.0
此时我们就可以先通过命令行来测试一下是否可以正常运行了
paddleocr ocr -i photo.jpg
在第一次运行的时候会自动帮我们下载好模型 输出结果中rec_texts就是我们想要的ocr识别内容

简单的脚本使用
这里需要注意paddle3.0不在使用cls 而是使用predict参数
# paddle3.0
from paddleocr import PaddleOCR
# ocr = PaddleOCR() # 文本图像预处理+文本检测+方向分类+文本识别
# ocr = PaddleOCR(use_doc_orientation_classify=False, use_doc_unwarping=False) # 文本检测+方向分类+文本识别
ocr = PaddleOCR(use_doc_orientation_classify=False, use_doc_unwarping=False, use_textline_orientation=False) # 文本检测+文本识别
result = ocr.predict("photo.jpg")
for res in result:
res.print()
res.save_to_img("output")
res.save_to_json("output")
对比一下 2.x版本的
from paddleocr import PaddleOCR, draw_ocr
# 模型路径下必须含有model和params文件
ocr = PaddleOCR(det_model_dir='{your_det_model_dir}', rec_model_dir='{your_rec_model_dir}',
rec_char_dict_path='{your_rec_char_dict_path}', cls_model_dir='{your_cls_model_dir}',
use_angle_cls=True)
img_path = 'PaddleOCR/doc/imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/path/to/PaddleOCR/doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
批量识别图片脚本
import os
from paddleocr import PaddleOCR
# 图片存放路径
image_folder = './photos'
ocr = PaddleOCR(use_doc_orientation_classify=False, use_doc_unwarping=False, use_textline_orientation=False)
image_files = [f for f in os.listdir(image_folder)
if os.path.isfile(os.path.join(image_folder, f))]
count = 0
for image_file in image_files:
try:
image_path = os.path.join(image_folder, image_file)
print(f"Processing: {image_path}")
result = ocr.predict(image_path)
# 只提取 rec_texts 部分
if result and isinstance(result, list) and len(result) > 0:
rec_texts = result[0].get('rec_texts', [])
if rec_texts:
print(rec_texts)
else:
print("未识别到文本内容")
count += 1
else:
print("无识别结果")
count += 1
except KeyboardInterrupt:
print("\n收到中断,退出程序。")
break
except Exception as e:
print(f"处理 {image_file} 时出错: {str(e)}")
count += 1
continue
print(f'未识别到内容的图片数量:{count}')
下面这个是按照图片中一定的数字顺序 同时可以将结果放到一个txt文件中
import os
import re
from paddleocr import PaddleOCR
image_folder = './photos'
ocr = PaddleOCR(use_doc_orientation_classify=False, use_doc_unwarping=False, use_textline_orientation=False)
image_files = [f for f in os.listdir(image_folder)
if os.path.isfile(os.path.join(image_folder, f))]
def extract_number(filename):
"""从文件名中提取数字部分"""
match = re.search(r'photo_(\d+)@', filename)
if match:
return int(match.group(1))
return float('inf')
image_files.sort(key=extract_number)
count = 0
processed_count = 0
total_images = len(image_files)
# 创建结果文件
with open('results.txt', 'w', encoding='utf-8') as result_file:
for image_file in image_files:
try:
image_path = os.path.join(image_folder, image_file)
processed_count += 1
print(f"处理中{image_file}")
# 文件写入处理信息
result_file.write(f"图片: {image_file}\n")
result = ocr.predict(image_path)
# 提取 rec_texts 部分
if result and isinstance(result, list) and len(result) > 0:
rec_texts = result[0].get('rec_texts', [])
if rec_texts:
print('识别文本:', rec_texts)
result_file.write(f" {rec_texts}\n")
else:
print("未识别到文本内容")
count += 1
else:
print("无识别结果")
count += 1
except KeyboardInterrupt:
print("收到中断,退出程序。")
break
except Exception as e:
print(f"处理时出错: {str(e)}")
count += 1
continue
result_file.write(f"处理完成! 总图片数: {total_images}\n")
result_file.write(f"成功识别: {total_images - count}\n")
result_file.write(f"未识别/失败: {count}\n")
# 控制台输出总结
print(f'\n处理完成! 未识别到内容的图片数量:{count}/{total_images}')
print(f"结果已保存到 results.txt")