
2024国城杯Misc wp
2024国城杯Misc wp
取证
说了取证有四部分 先取证大师+火眼整一下
先看到桌面有个流量包
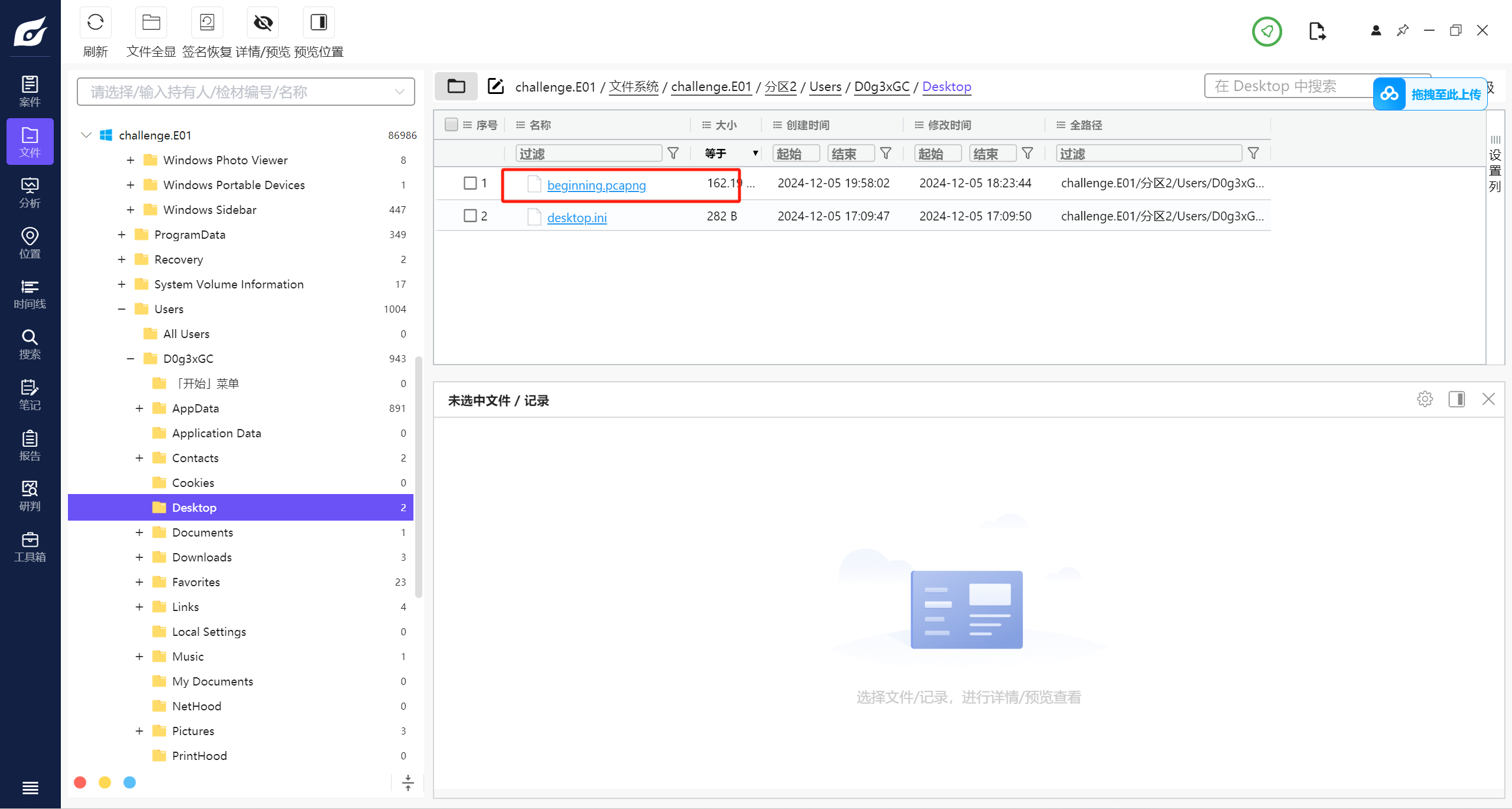
提出来 发现藏了一张jpg图片
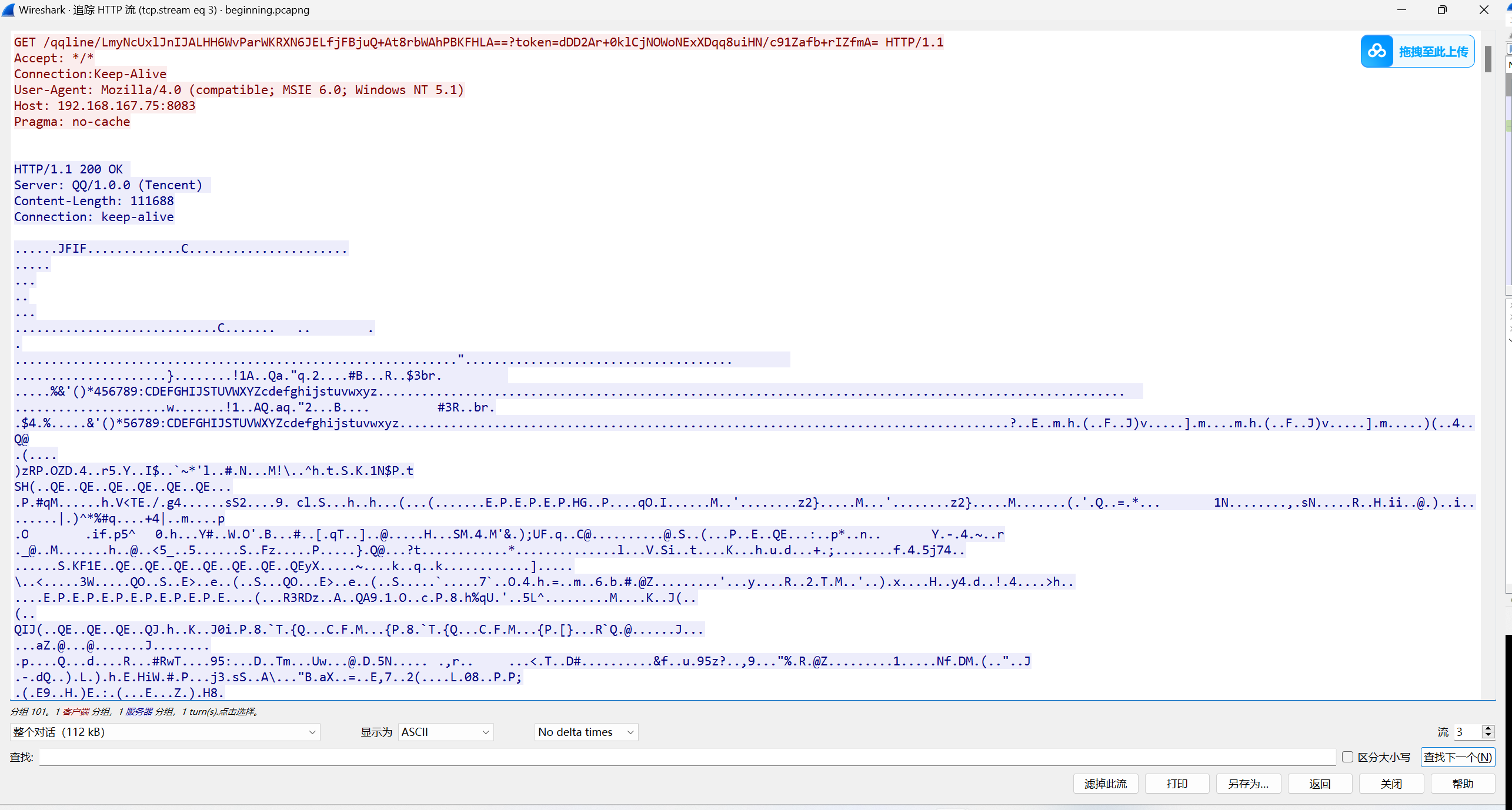
提出来 放010看一下 有一串base64
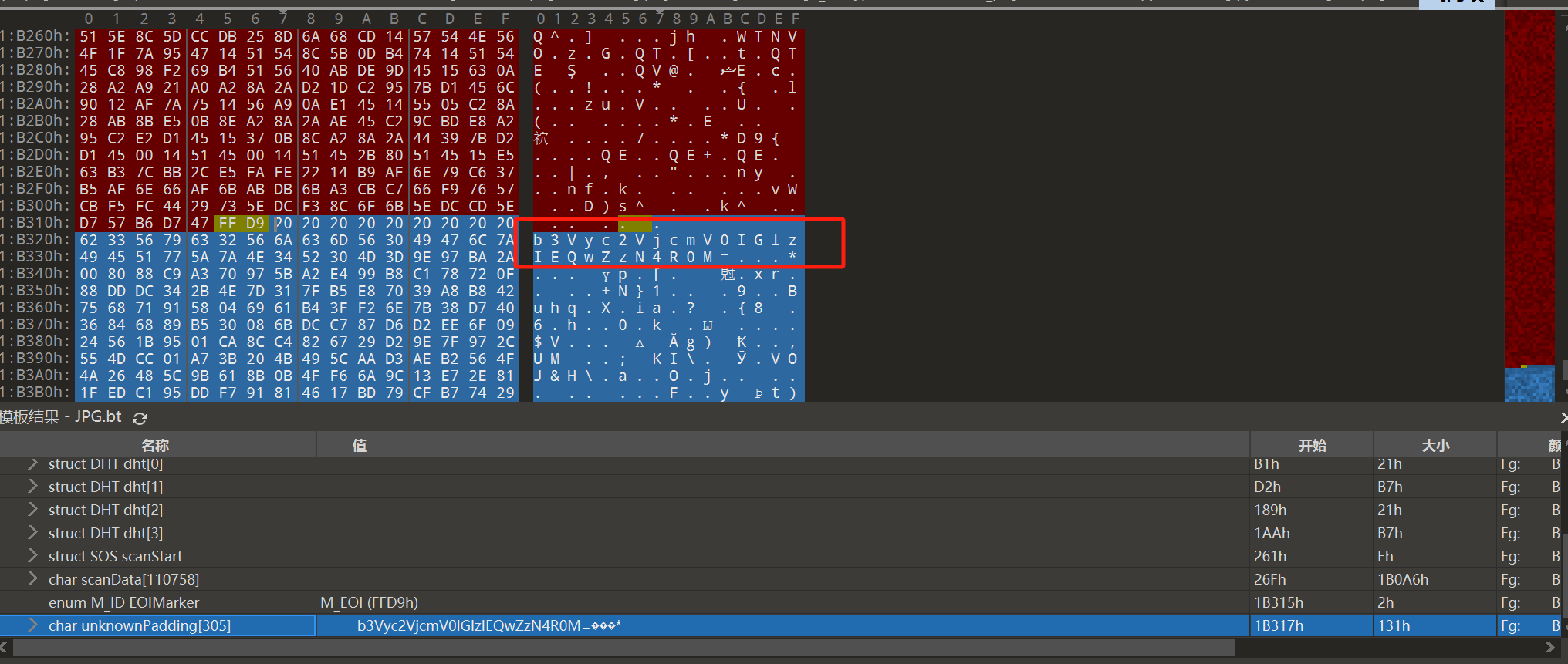
解一下 提示oursecret
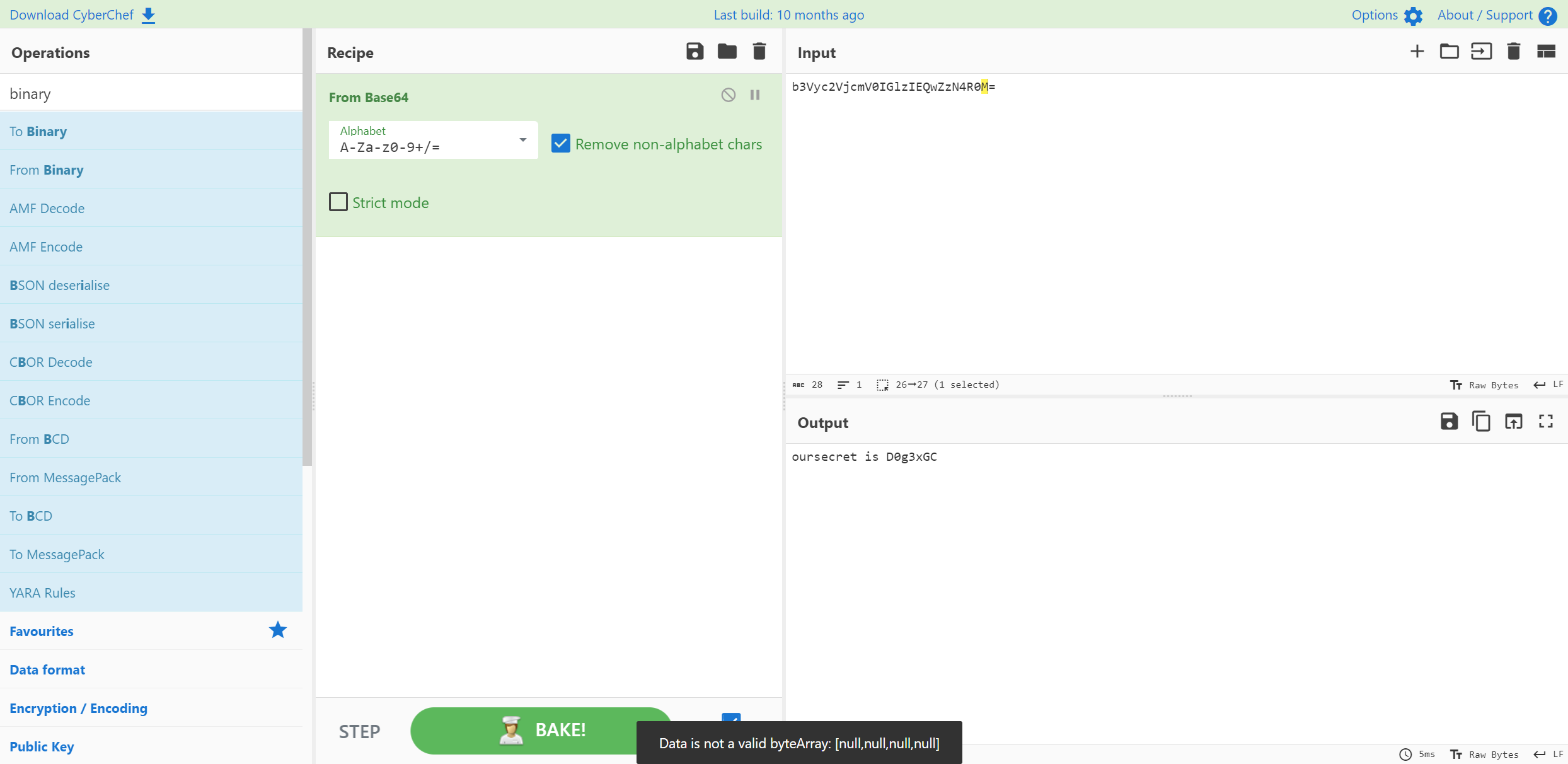
使用oursecret来解密 提出来一个hidden.txt
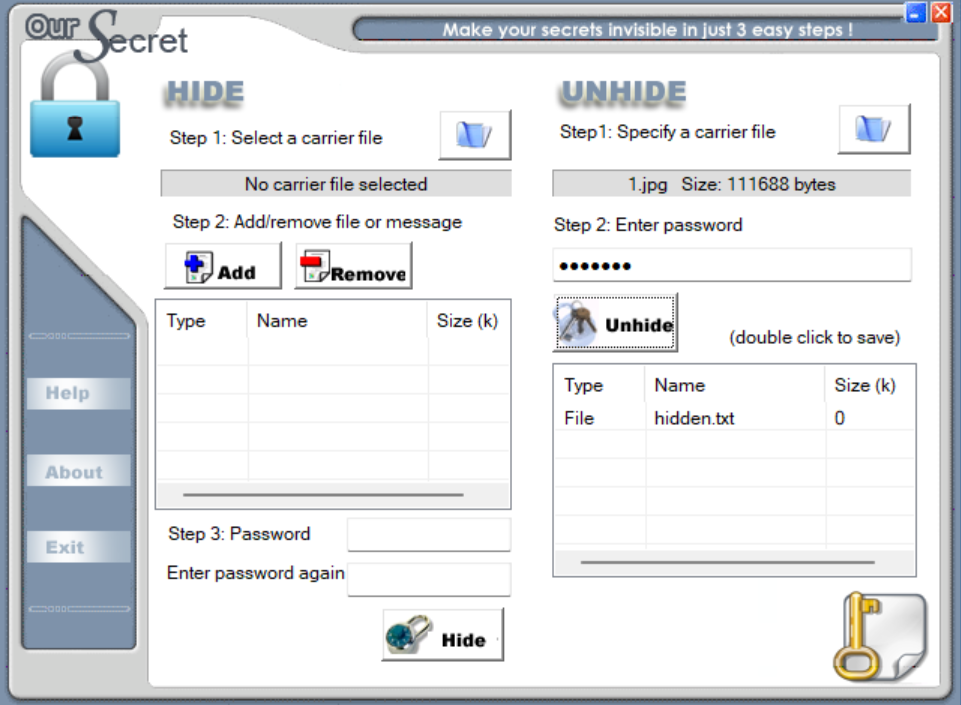
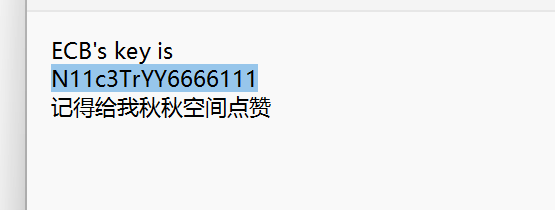
提示QQ空间 正好上面流量是QQ的OICQ协议流量 发现直接给了一个QQ号
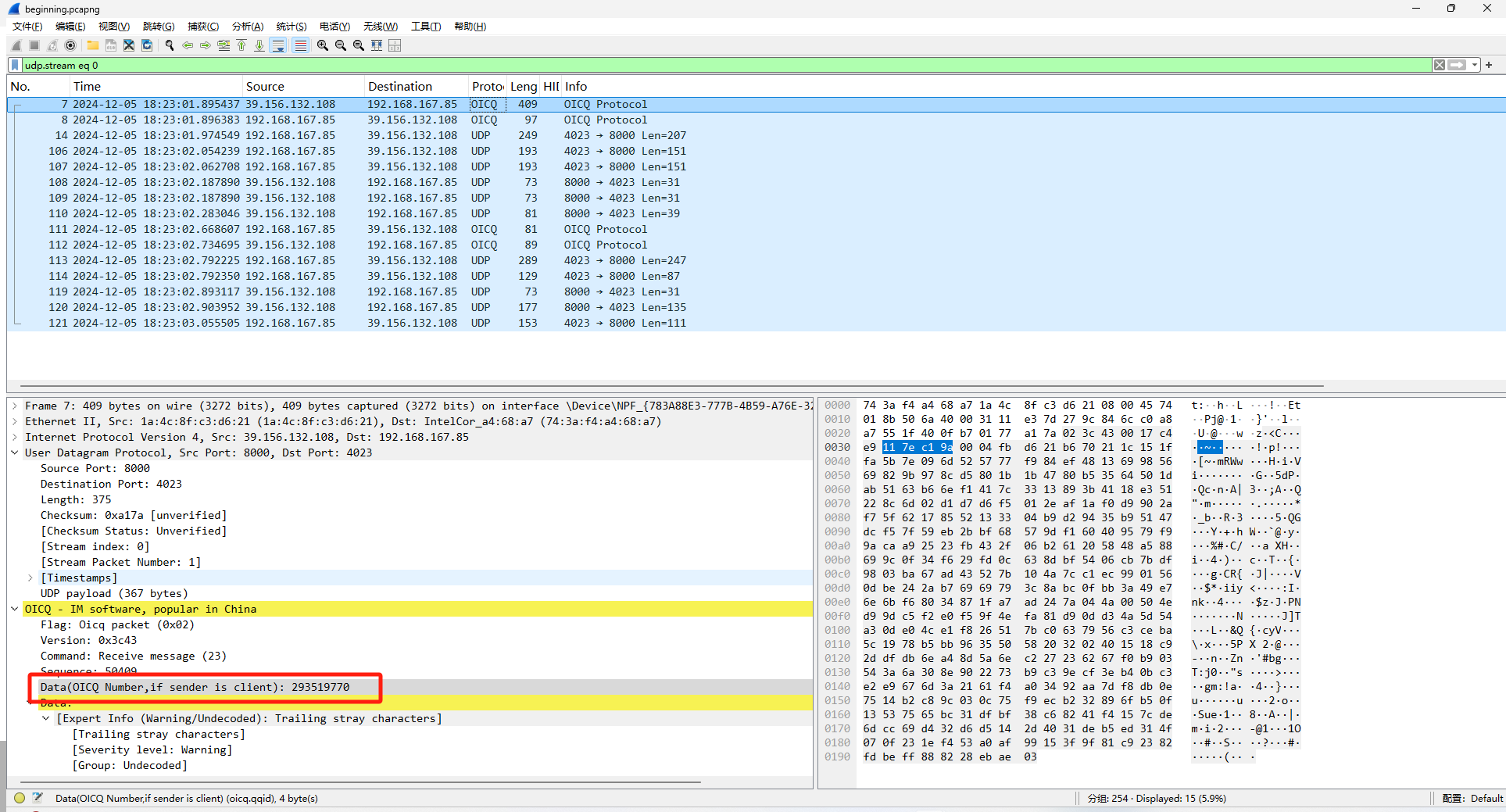
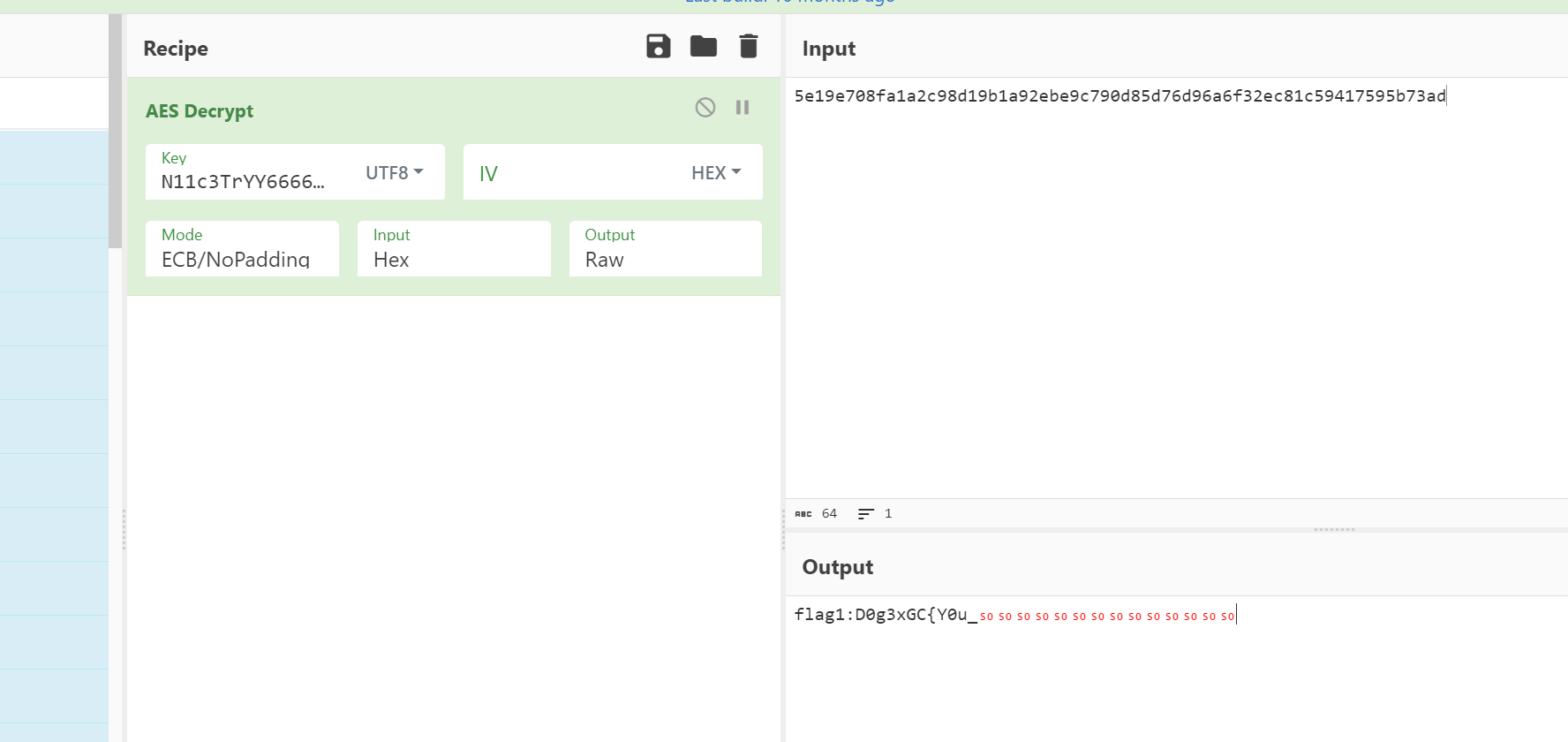
搜索一下 在QQ空间说说中找到密文

直接aes-ecb解 拿到flag1
在压缩文件中找到一个flag4
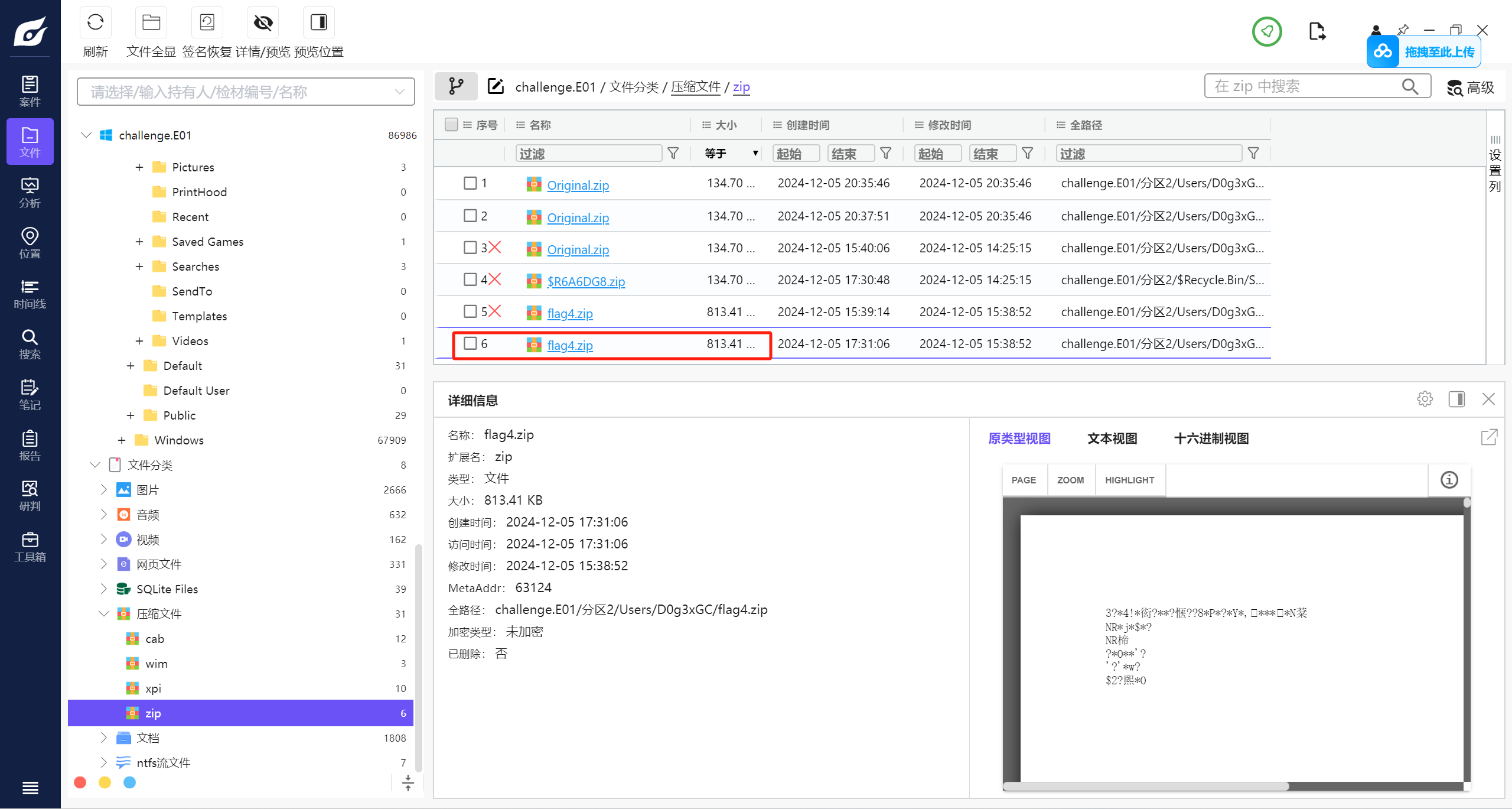
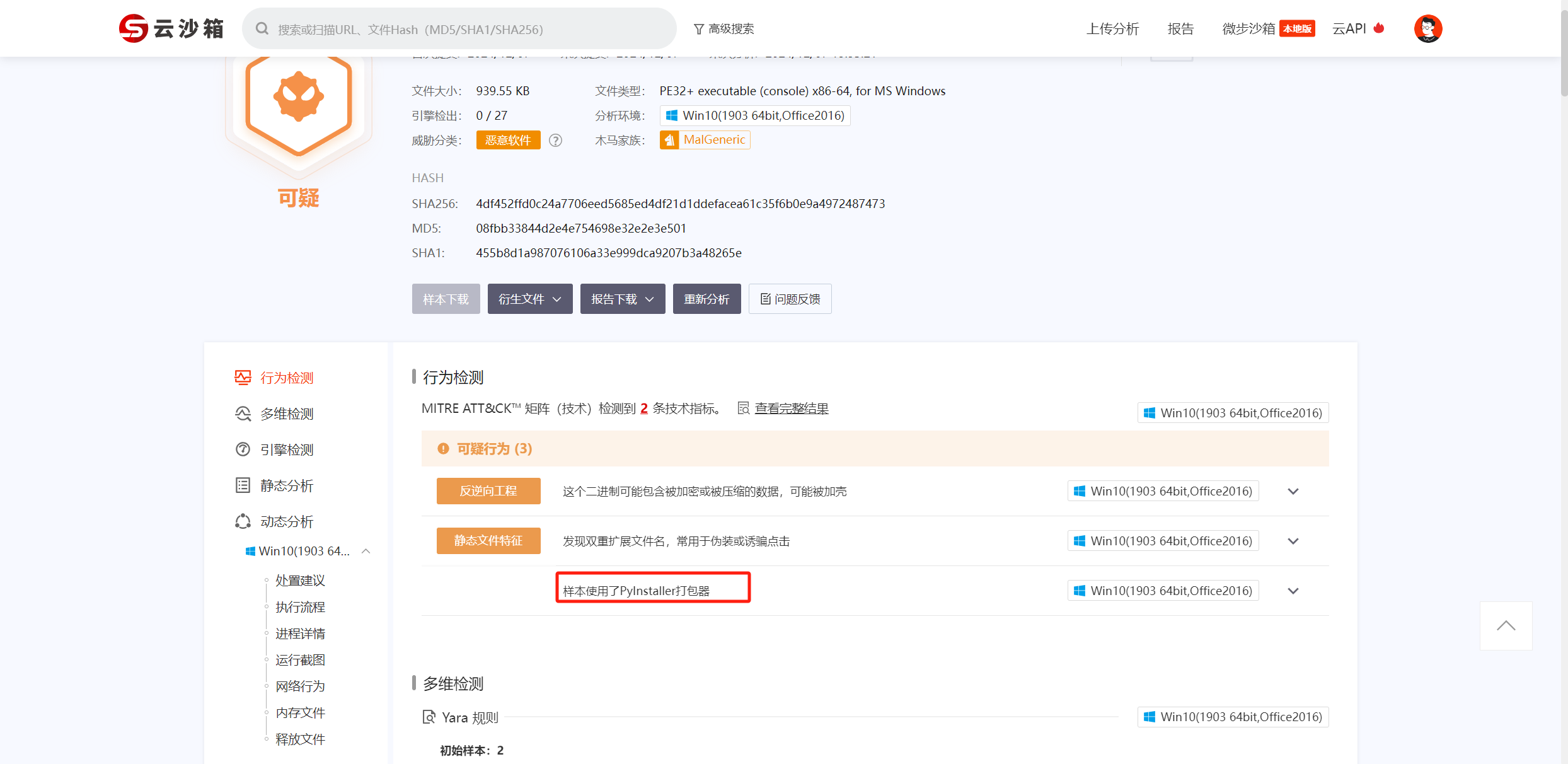
可以直接解压 exe放沙箱里面分析一下
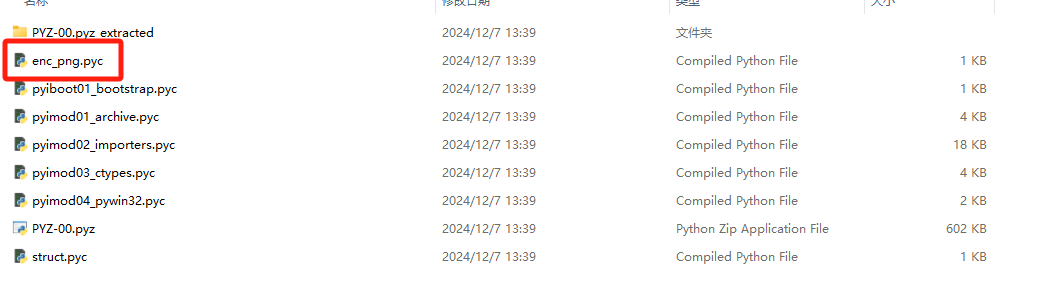
用pyinstxtractor解包 找到关键的pyc文件
在线反编译 拿到加密代码
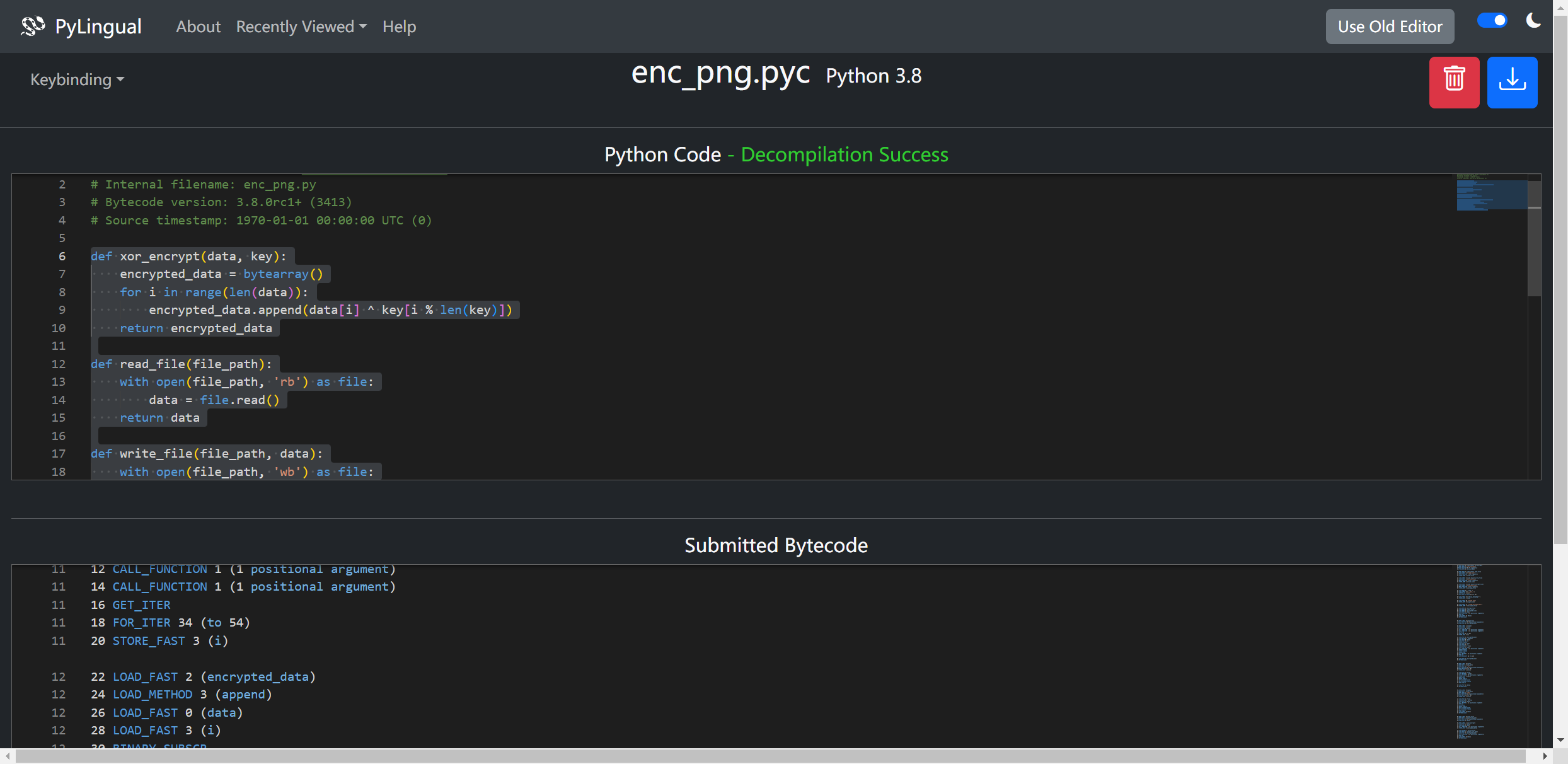
写出解密代码
def xor_decrypt(encrypted_data, key):
decrypted_data = bytearray()
for i in range(len(encrypted_data)):
decrypted_data.append(encrypted_data[i] ^ key[i % len(key)])
return decrypted_data
def read_file(file_path):
with open(file_path, 'rb') as file:
data = file.read()
return data
def write_file(file_path, data):
with open(file_path, 'wb') as file:
file.write(data)
def decrypt_file(input_file_path, output_file_path, key):
encrypted_data = read_file(input_file_path)
decrypted_data = xor_decrypt(encrypted_data, key)
write_file(output_file_path, decrypted_data)
if __name__ == '__main__':
key = b'GCcup_wAngwaNg!!'
encrypted_file = 'flag4_encrypted.bin'
decrypted_file = 'flag4_decrypted.png'
decrypt_file(encrypted_file, decrypted_file, key)
拿到flag4

还能找到一个修改了后缀名的压缩包 名为2
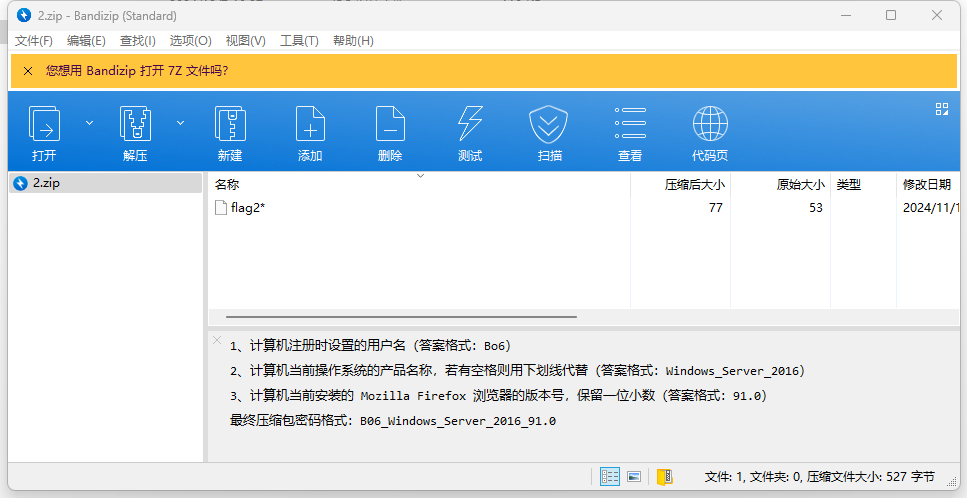
根据要求 得到密码是
D0g3xGC_Windows_7_Ultimate_115.0
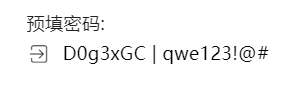
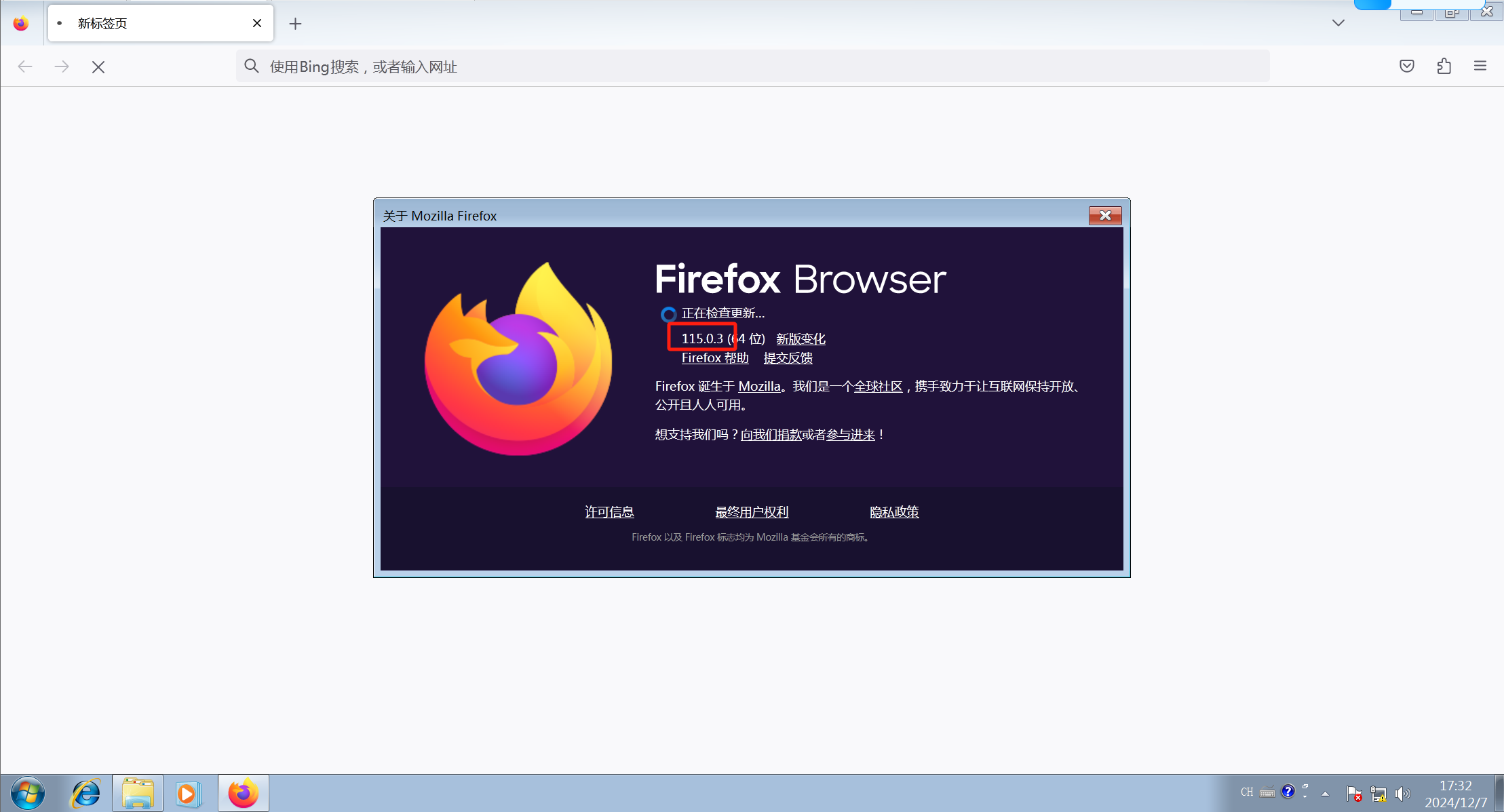
flag2放到赛博厨子里面解一下
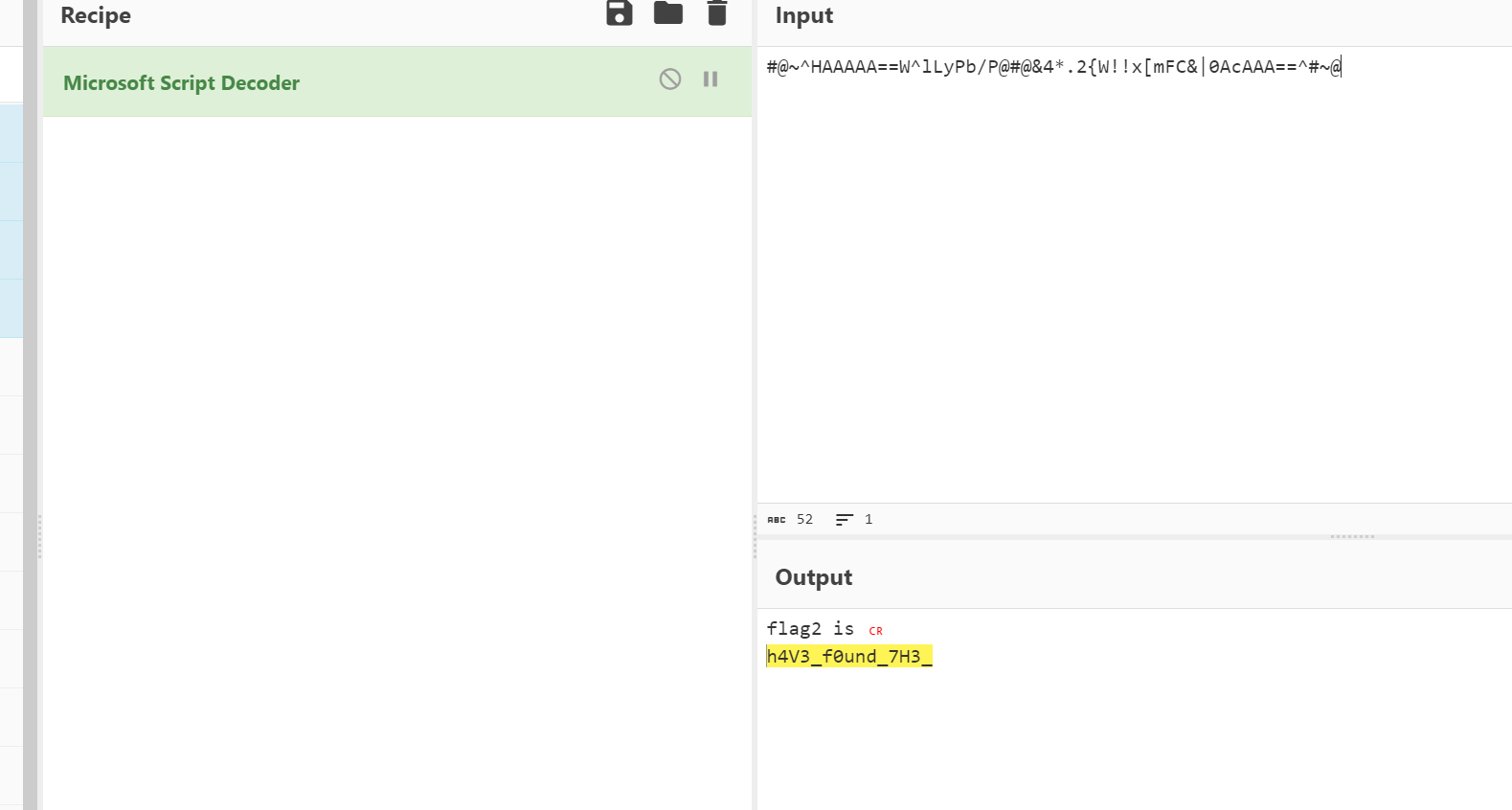
还找到一个Original.zip
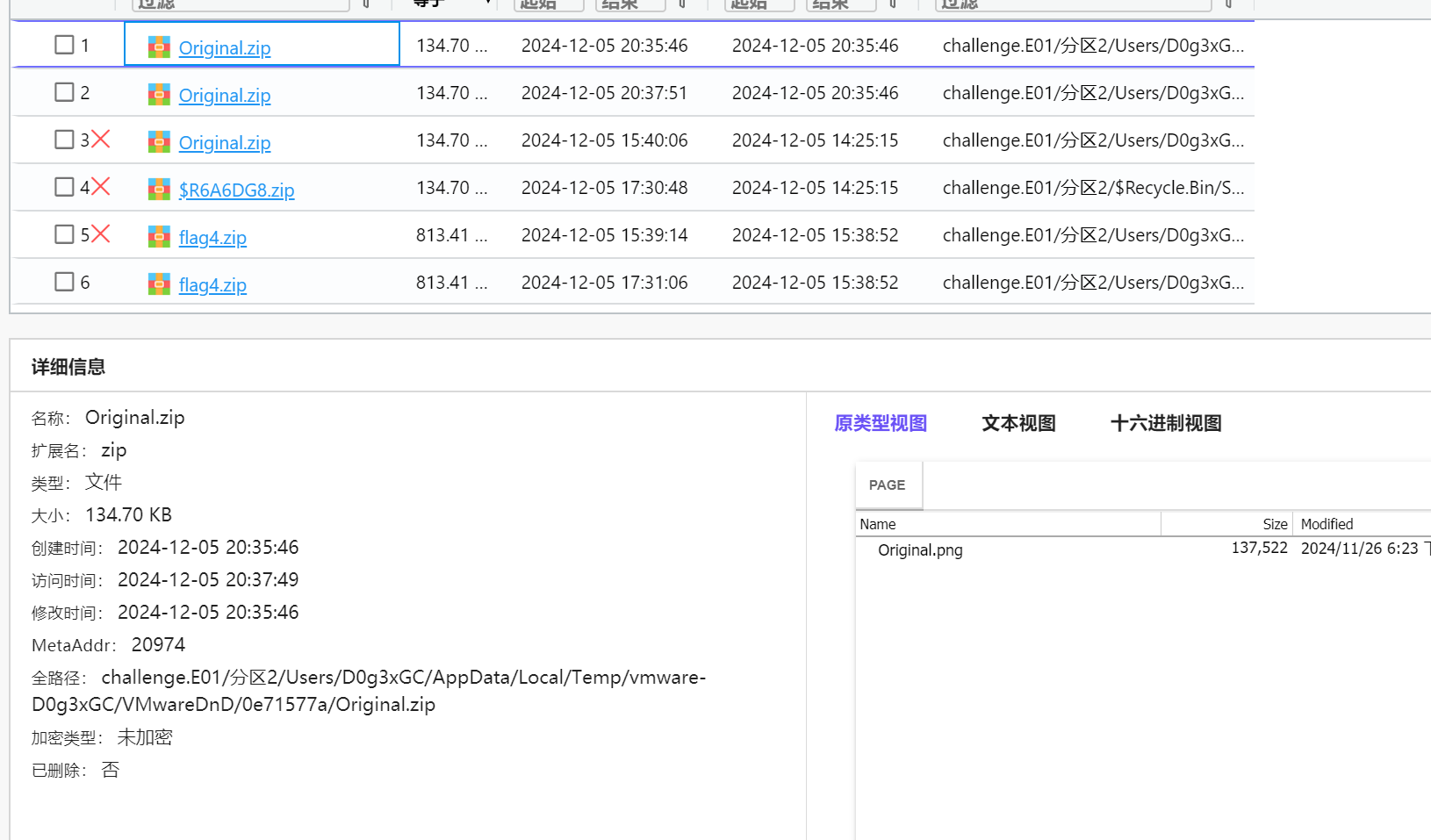
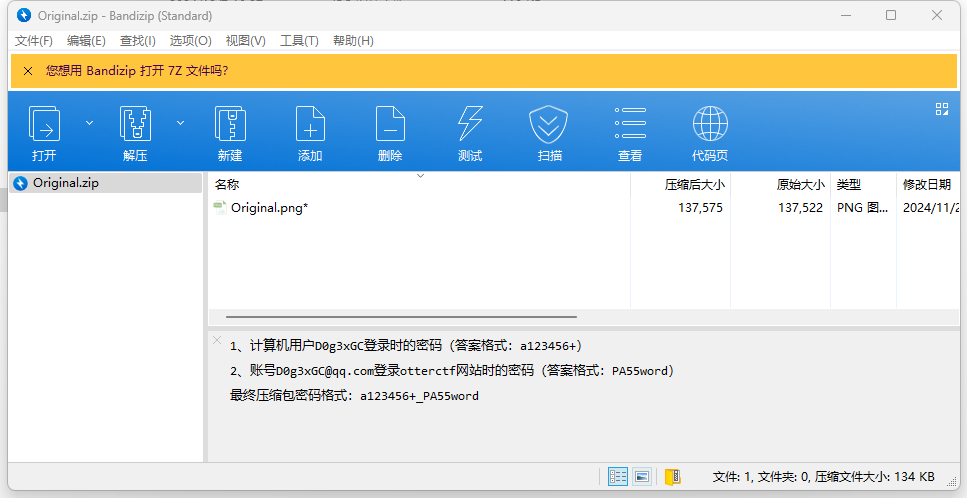
得到解压密码
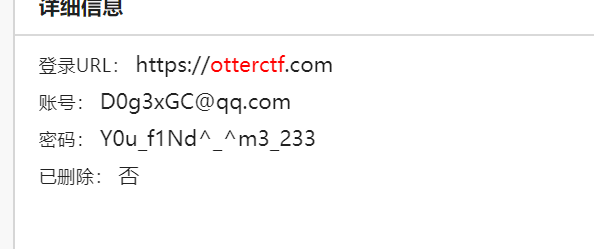
qwe123!@#_Y0u_f1Nd^_^m3_233
还找到一张和Original.zip解压出来看起来很相似的一张图片
根据名字 找到一个项目
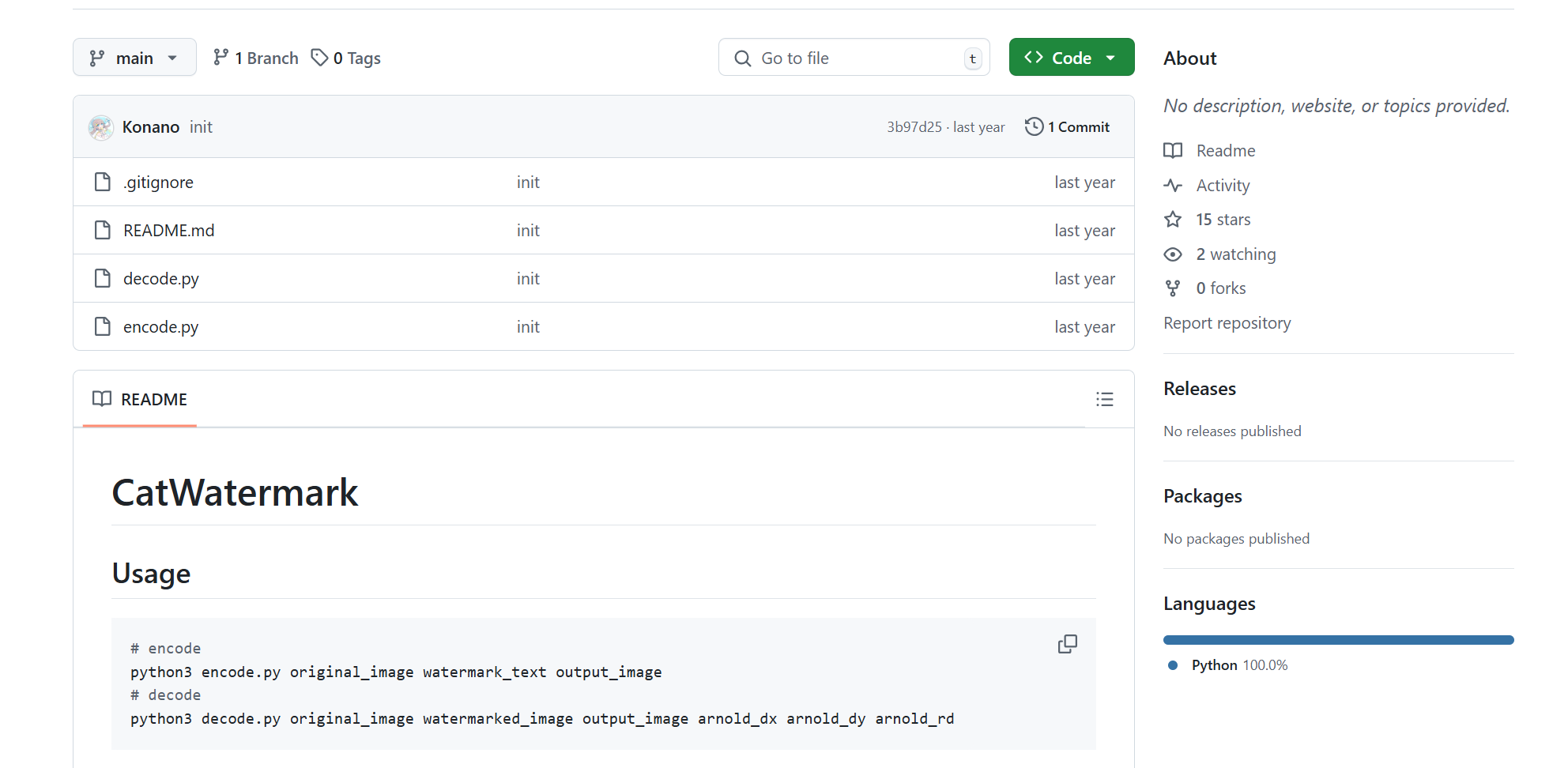
根据这篇文章的代码得知 变换次数恒为1
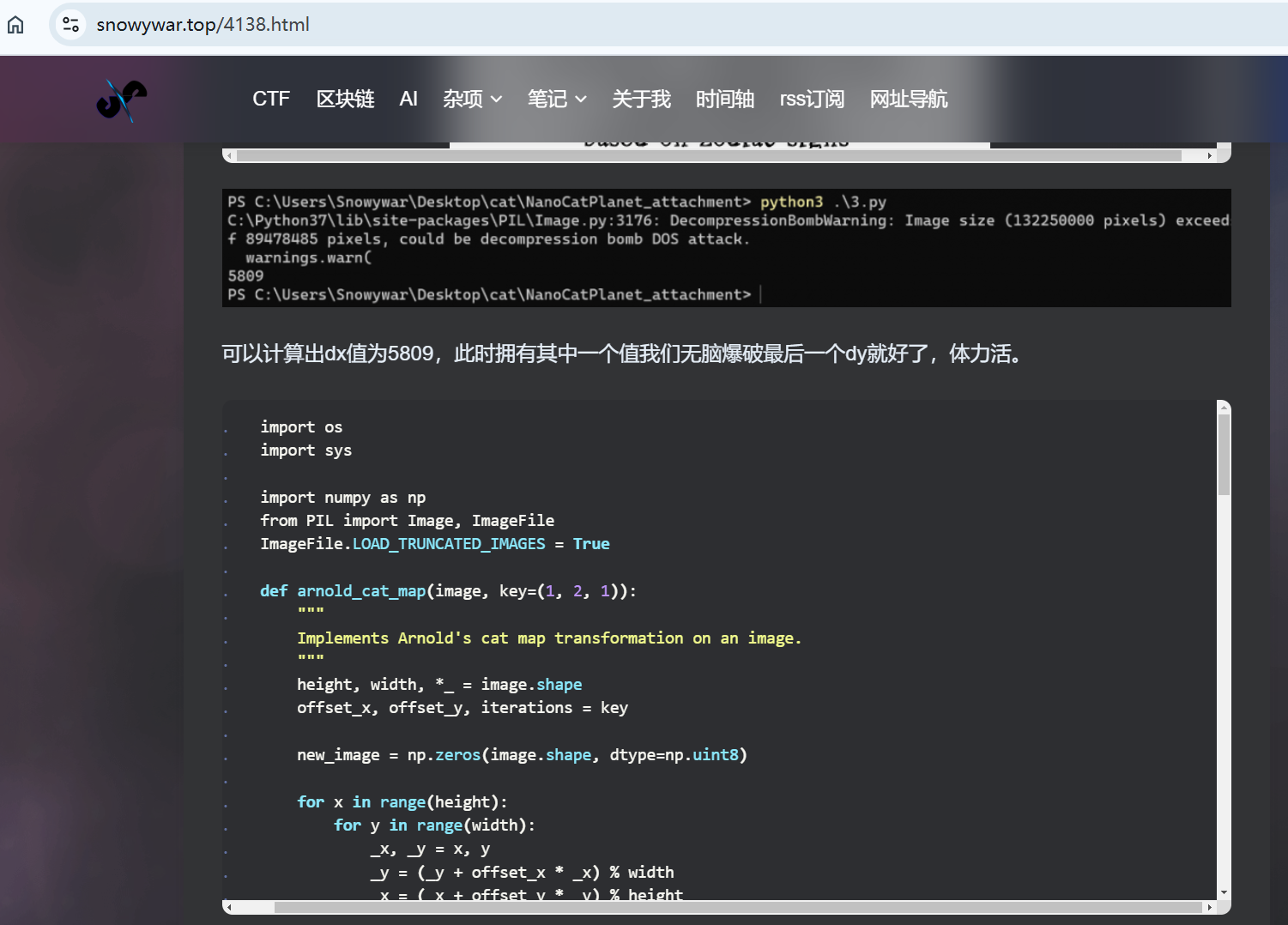
但是看到上面项目中的加密脚本里面写的了三个参数dx dy rd的范围都比较小 我们这里已知rd恒为1 可以写脚本进行交叉爆破

import os
import sys
import numpy as np
from PIL import Image, ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
def arnold_cat_map(image, key=(1, 2, 1)):
"""
Implements Arnold's cat map transformation on an image.
"""
height, width, *_ = image.shape
offset_x, offset_y, iterations = key
new_image = np.zeros(image.shape, dtype=np.uint8)
for x in range(height):
for y in range(width):
_x, _y = x, y
_y = (_y + offset_x * _x) % width
_x = (_x + offset_y * _y) % height
new_image[_x, _y] = image[x, y]
return new_image
def arnold_cat_map_rev(image, key=(1, 2, 1)):
"""
Implements Arnold's cat map transformation on an image (reverse).
"""
height, width, *_ = image.shape
offset_x, offset_y, iterations = key
new_image = np.zeros(image.shape, dtype=np.uint8)
for x in range(height):
for y in range(width):
_x, _y = x, y
_x = (_x - offset_y * _y) % height
_y = (_y - offset_x * _x) % width
new_image[_x, _y] = image[x, y]
return new_image
def extract_watermark(original_image_path, watermarked_image_path, output_image_path, private_key):
"""
Extracts a text watermark from a watermarked image using the Arnold's cat map transformation.
"""
# Open the original image
original_image = np.array(Image.open(original_image_path).convert("RGB"))
# Open the watermarked image
watermarked_image = np.array(Image.open(watermarked_image_path).convert("RGB"))
assert watermarked_image.shape == original_image.shape
# Extract the watermark from the watermarked image
original_image ^= watermarked_image
transformed_image = arnold_cat_map(original_image, private_key)
transformed_image[transformed_image > 0] = 255
transformed_image = 255 - transformed_image
# Save the extracted watermark
Image.fromarray(np.uint8(transformed_image)).save(output_image_path)
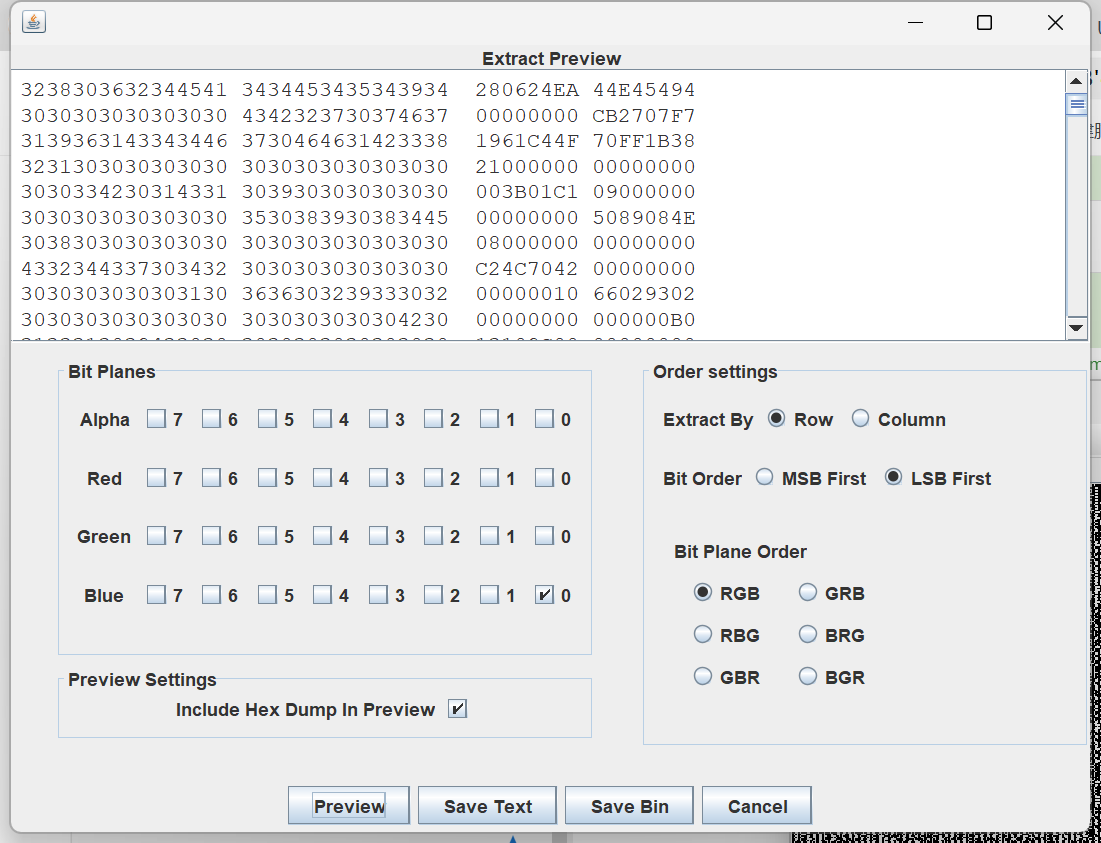
def try_arnold_dx_dy(original_image_path, watermarked_image_path, output_image_path, arnold_rd, dx_range, dy_range):
original_image = np.array(Image.open(original_image_path).convert("RGB"))
watermarked_image = np.array(Image.open(watermarked_image_path).convert("RGB"))
height, width, *_ = original_image.shape
# Iterate over the entire range of arnold_dx and arnold_dy
for arnold_dx in dx_range:
for arnold_dy in dy_range:
private_key = (arnold_dx, arnold_dy, arnold_rd)
# Perform the transformation
extracted_watermark = arnold_cat_map(original_image ^ watermarked_image, private_key)
extracted_watermark[extracted_watermark > 0] = 255
extracted_watermark = 255 - extracted_watermark
# Save the result with the current arnold_dx and arnold_dy in the filename
output_filename = f"{output_image_path}_arnold_dx_{arnold_dx}_arnold_dy_{arnold_dy}.png"
Image.fromarray(np.uint8(extracted_watermark)).save(output_filename)
print(f"Saved {output_filename} with arnold_dx = {arnold_dx}, arnold_dy = {arnold_dy}")
# 输入参数检查
if len(sys.argv) != 4:
print("Usage: brute_force_arnold_dx_dy.py original_image watermarked_image output_image")
sys.exit(1)
original_image_path = sys.argv[1]
watermarked_image_path = sys.argv[2]
output_image_path = sys.argv[3]
# 定义arnold_rd为1
arnold_rd = 1
# 设置爆破范围
dx_range = range(164, 264) # arnold_dx 范围从 43 到 385
dy_range = range(21, 186) # arnold_dy 范围从 21 到 185
# 开始爆破 arnold_dx 和 arnold_dy
try_arnold_dx_dy(original_image_path, watermarked_image_path, output_image_path, arnold_rd, dx_range, dy_range)
最后找到一张看起来比较清楚的一张图片

F1N4L_s3CR3t_0F_Th15_
拼起来就是
D0g3xGC{Y0u_h4V3_f0und_7H3_F1N4L_s3CR3t_0F_Th15_F0R3N51c5_Ch4Ll3N93}
Tr4ffIc_w1th_Ste90
流量中追踪udp流 找到一个视频文件
这边先是原始数据保存出来 如果不知道文件类型的话 可以使用magika识别一下

打开视频 发现解压密码
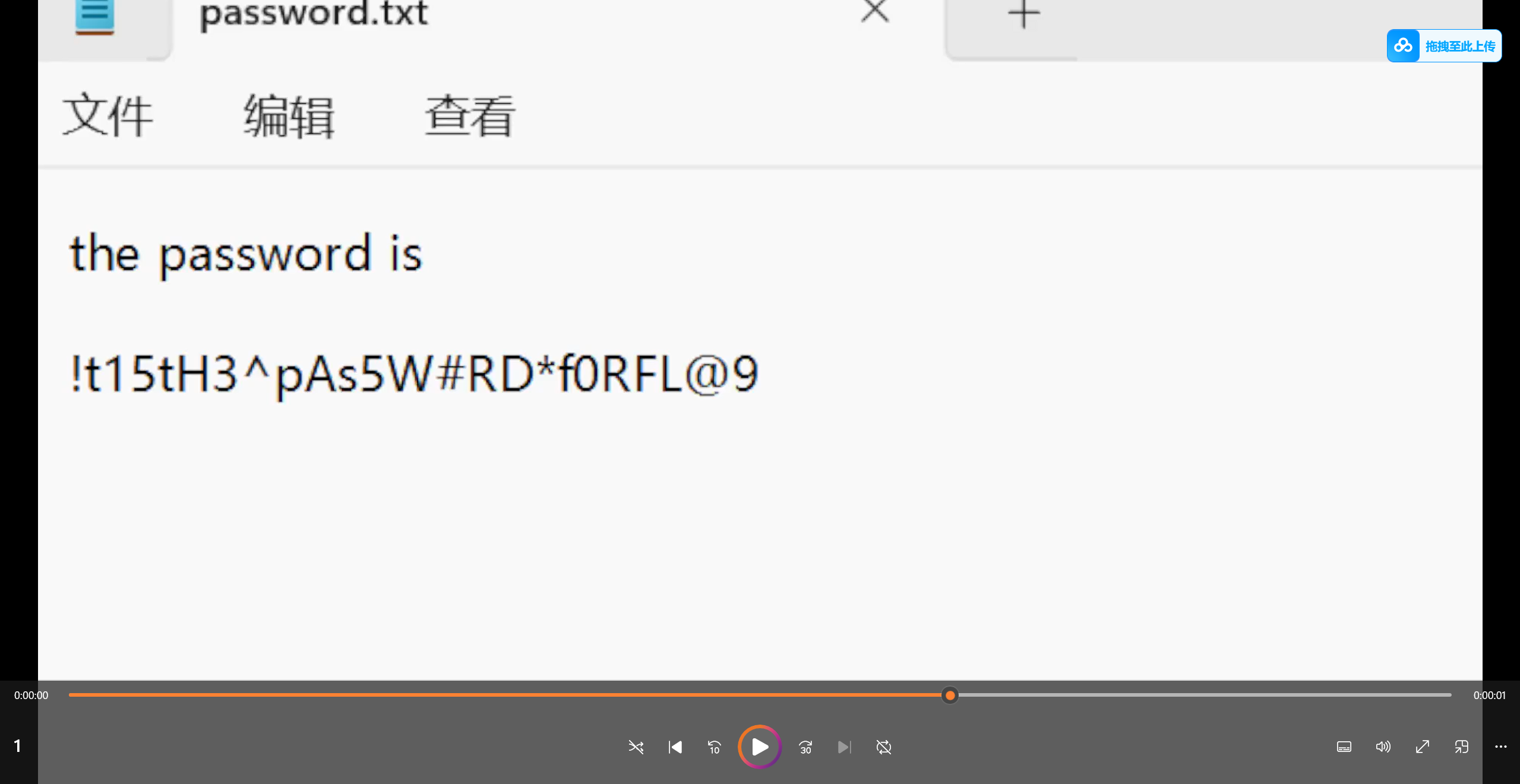
得到加密图片和加密脚本 根据加密脚本 我们得知加密脚本使用的种子范围是50-70 我们可以写解密脚本爆破解密
import numpy as np
import cv2
import os
def decode(input_image, output_image, seed):
"""
Decode the given image using the specified seed.
"""
np.random.seed(seed)
to_decode = cv2.imread(input_image, cv2.IMREAD_GRAYSCALE)
if to_decode is None:
print(f"Error: Unable to load image {input_image}")
return False
to_decode_array = np.asarray(to_decode)
row_indices = list(range(to_decode_array.shape[0]))
col_indices = list(range(to_decode_array.shape[1]))
np.random.shuffle(row_indices)
np.random.shuffle(col_indices)
# Generate reverse indices to undo the shuffling
row_reverse_indices = [row_indices.index(i) for i in range(to_decode_array.shape[0])]
col_reverse_indices = [col_indices.index(i) for i in range(to_decode_array.shape[1])]
# Undo the shuffle by using the reverse indices
to_decode_array = to_decode_array[row_reverse_indices, :]
to_decode_array = to_decode_array[:, col_reverse_indices]
# Convert the image back to BGR for visualization
decoded_image = cv2.cvtColor(to_decode_array, cv2.COLOR_GRAY2BGR)
cv2.imwrite(output_image, decoded_image)
print(f"Decoded image saved as {output_image}")
return True
def brute_force_decode(input_image, output_dir, seed_start, seed_end):
"""
Brute force the decryption using a range of seeds.
"""
if not os.path.exists(output_dir):
os.makedirs(output_dir)
for seed in range(seed_start, seed_end + 1):
output_image = os.path.join(output_dir, f"decoded_{seed}.png")
success = decode(input_image, output_image, seed)
if not success:
print(f"Failed to decode image with seed {seed}")
if __name__ == '__main__':
input_image = "encoded.png"
output_dir = "decoded_images"
seed_start = 50
seed_end = 70
brute_force_decode(input_image, output_dir, seed_start, seed_end)
找到正确的解密图片

在线扫码识别一下
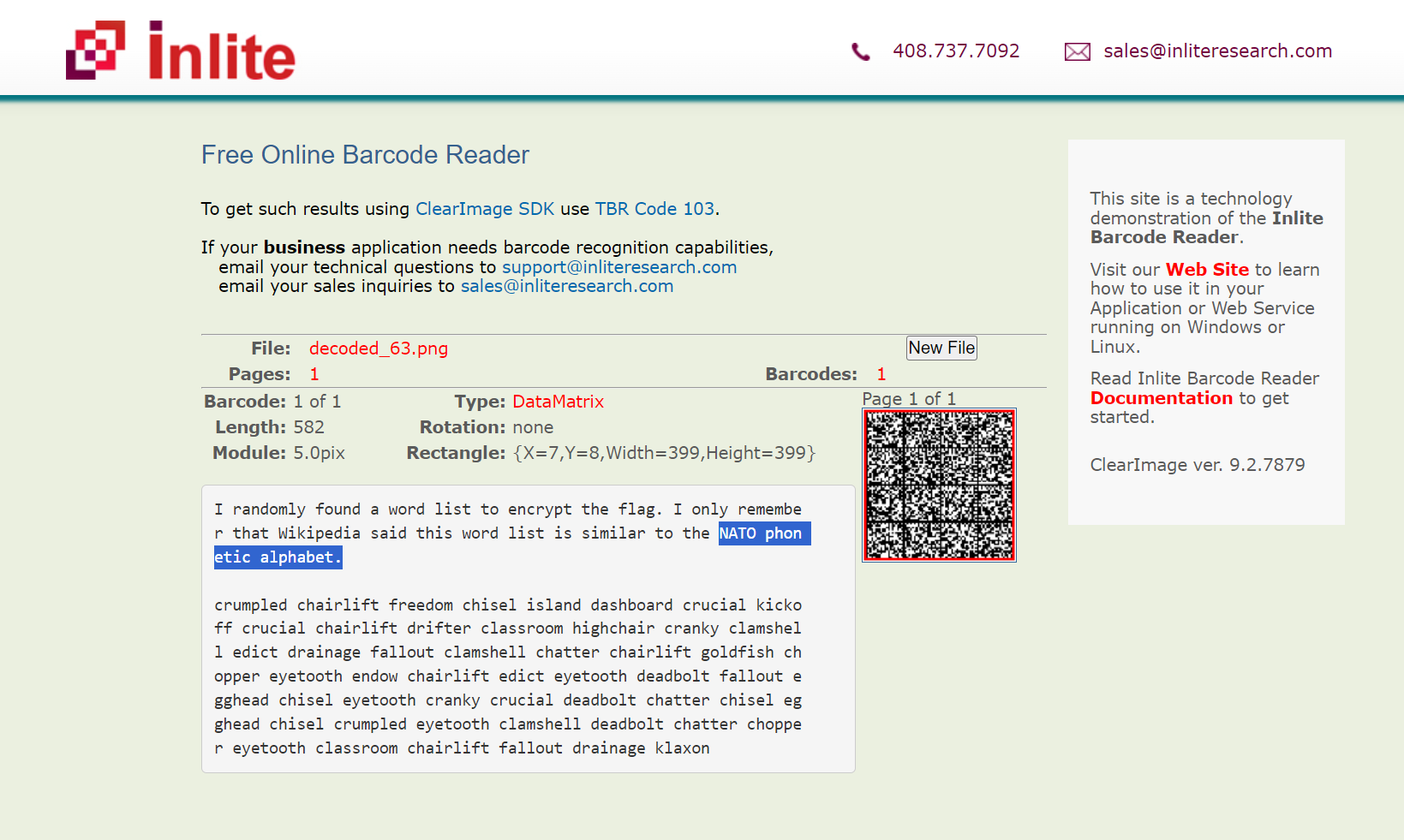
I randomly found a word list to encrypt the flag. I only remembe
r that Wikipedia said this word list is similar to the NATO phon
etic alphabet.
crumpled chairlift freedom chisel island dashboard crucial kicko
ff crucial chairlift drifter classroom highchair cranky clamshel
l edict drainage fallout clamshell chatter chairlift goldfish ch
opper eyetooth endow chairlift edict eyetooth deadbolt fallout e
gghead chisel eyetooth cranky crucial deadbolt chatter chisel eg
ghead chisel crumpled eyetooth clamshell deadbolt chatter choppe
r eyetooth classroom chairlift fallout drainage klaxon
意思是找了一个类似于NATO phonetic alphabet的字典进行了加密 我们也不用找这个NATO phonetic alphabet 直接去搜下面的密文 发现是PGP词汇表
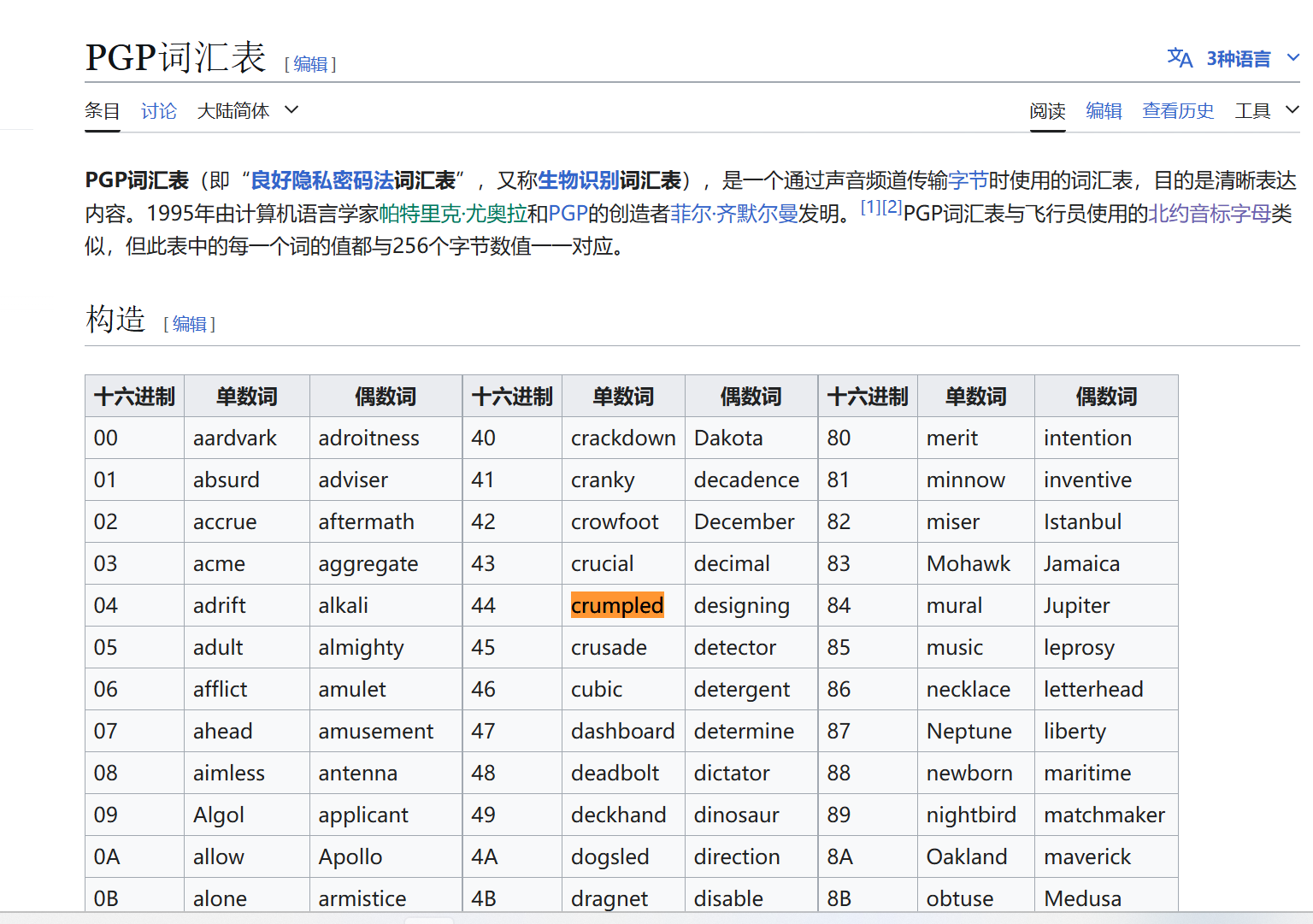
直接根据映射关系 得到了解密的16进制数据
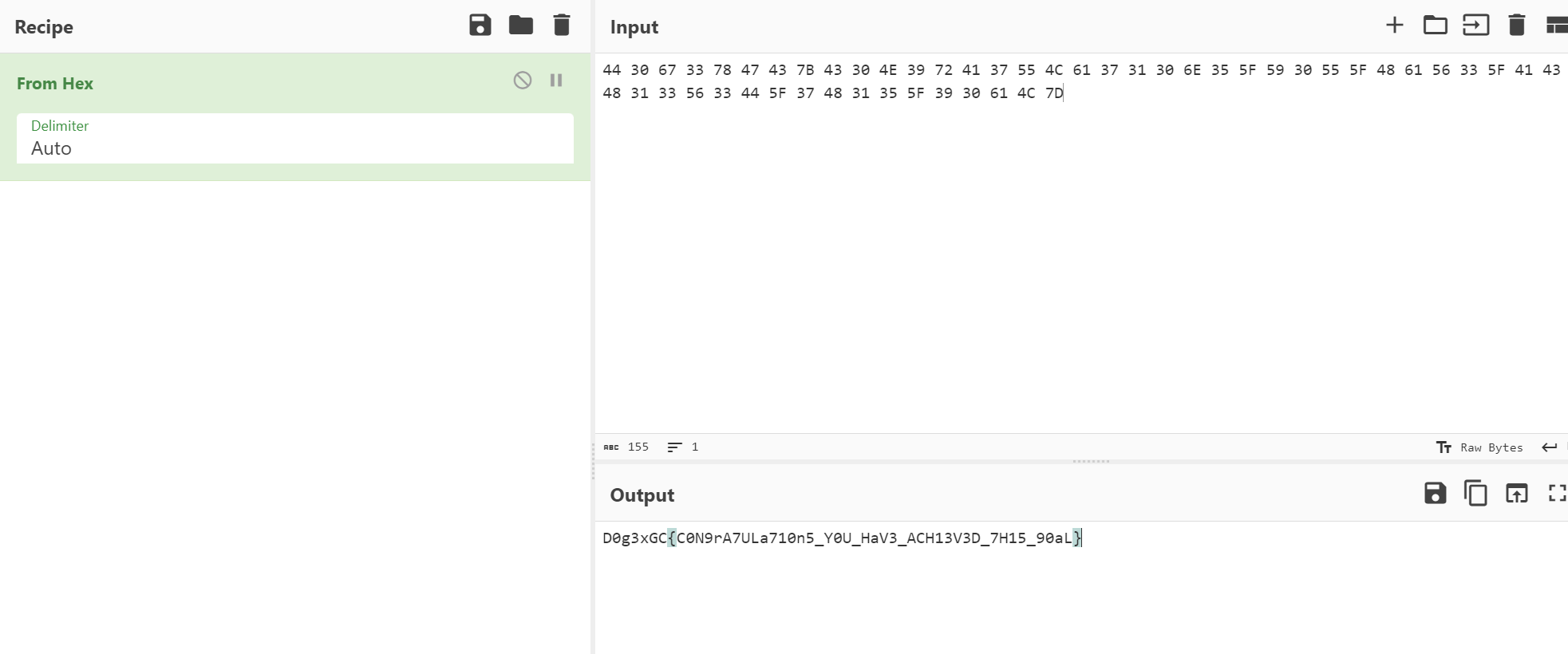
44 30 67 33 78 47 43 7B 43 30 4E 39 72 41 37 55 4C 61 37 31 30 6E 35 5F 59 30 55 5F 48 61 56 33 5F 41 43 48 31 33 56 33 44 5F 37 48 31 35 5F 39 30 61 4C 7D
解密得到flag
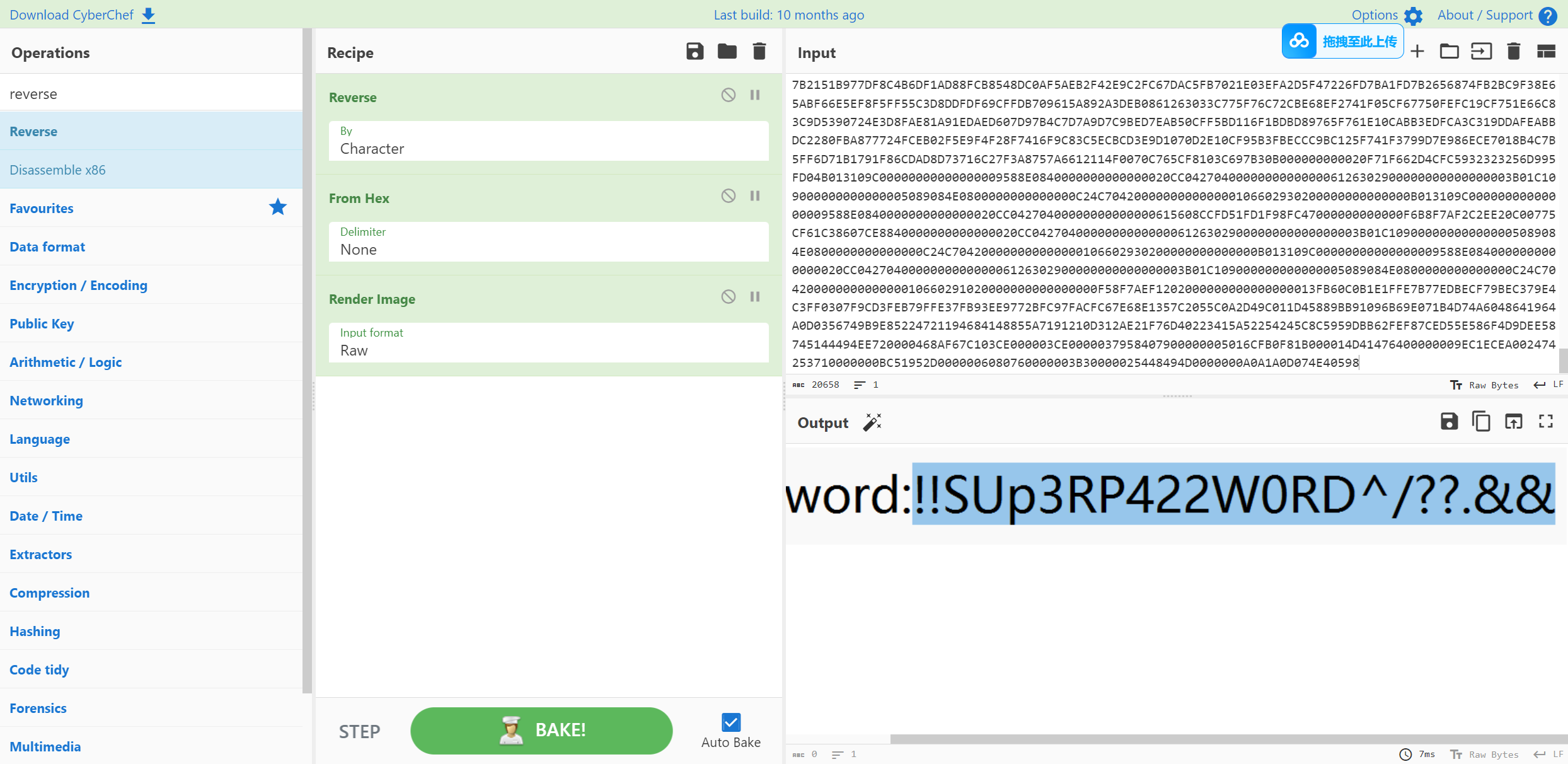
eZ_Steg0
给的01.png使用stegsolve看一下
提出来的数据 re一下 在解hex 得到一个password图片
使用给的password解压key.zip 打开看到key前部有base64字符串
解一下得到stl的提示
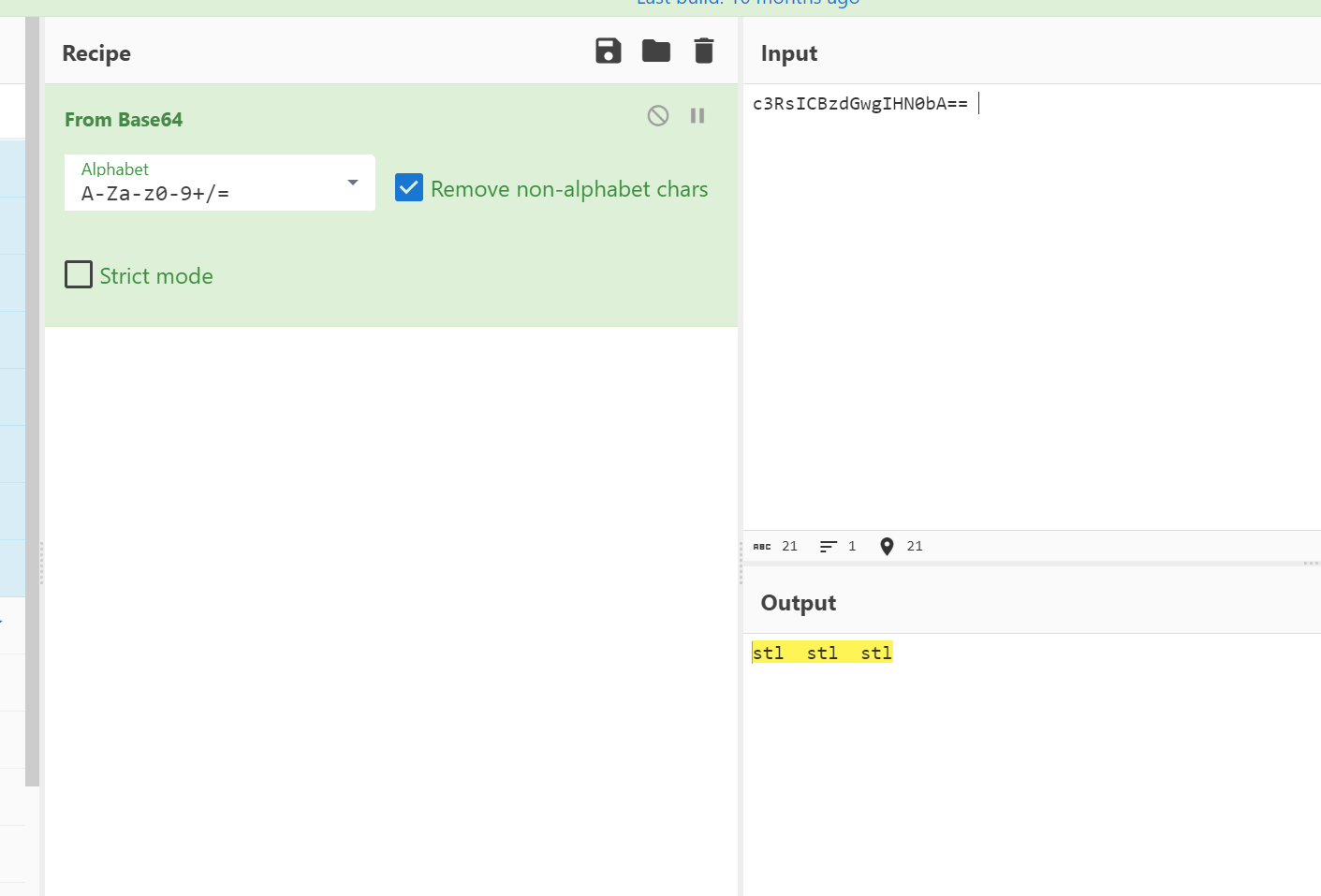
猜测是stl3D模型文件 删掉base64部分 改成stl后缀 可以直接用自带的3D查看器打开
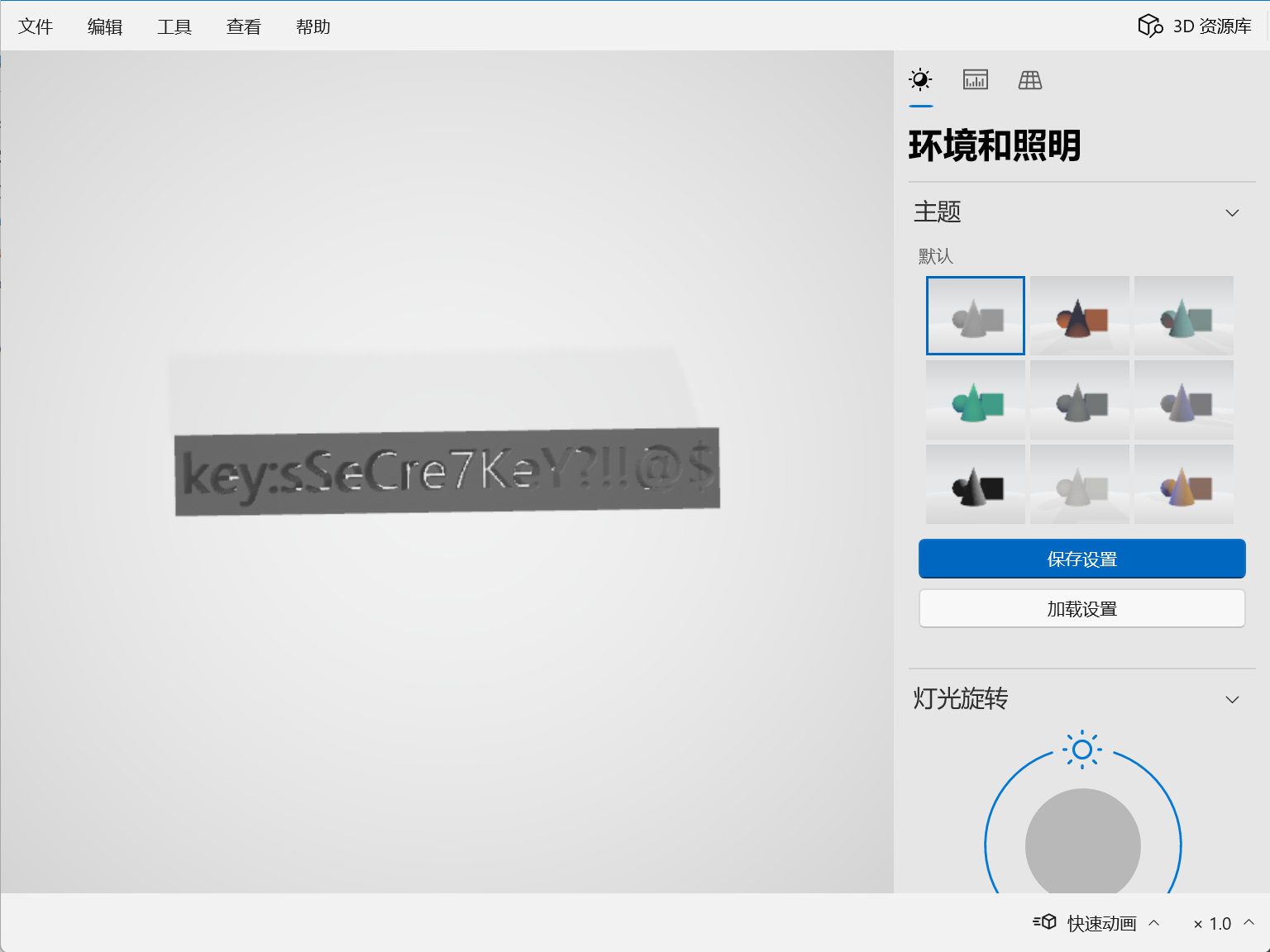
得到一个key
sSeCre7KeY?!!@$
在使用这个密钥和flag文件进行异或 得到一个wav文件
我们再来看一下音频 频谱图deepsound之类的都尝试过 没有结果 发现是音频的lsb隐写
import wave
def extract_lsb_from_wav(file_path):
with wave.open(file_path, mode='rb') as song:
frame_bytes = song.readframes(song.getnframes())
binary_string = ""
for byte in frame_bytes:
binary_string += bin(byte)[-1]
decoded_chars = []
for i in range(0, len(binary_string), 8):
byte = binary_string[i:i+8]
if len(byte) == 8:
decoded_chars.append(chr(int(byte, 2)))
decoded_message = ''.join(decoded_chars).split("###")[0]
return decoded_message
file_path = "download.wav"
decoded_message = extract_lsb_from_wav(file_path)
print( decoded_message)
